
Decentralization and scalability go hand-in-hand. The cheaper it is to operate a blockchain the more people can successfully replicate it and the more decentralized it will be. One of the major challenges faced by EOS and Hive is that they rely (or relied) upon an in-memory database whose performance drops dramatically once the data no longer fits in memory. This makes EOS RAM costs extremely high and also fundamentally limited to the amount of RAM that can be hosted within a single computer.
Hive eventually replaced chainbase (the memory mapped database) with a backend powered by a more traditional no-sql key/value database (Rocks DB). This allowed Hive to scale to more data storage at the expense of raw transactional throughput.
Unique Database Requirements of Blockchains
A blockchain is a database that can have multiple pending forks waiting for finality and all transactions are sequentially applied for determinism. This means the database cannot commit data until finality and may have to build on multiple partially validated states. In EOS, Hive, and BitShares we utilized an "undo history" which tracked changes and allowed us to quickly restore the state of the blockchain to an earlier version so that we could start applying the changes for a different fork.
This access pattern is fundamentally unfriendly for the transactional model of typical embedded no-sql databases such as RocksDB or LMDBX. Furthermore, even if a database supports multiple nested open "transactions", I have yet to find one that allows you to partially commit a confirmed part of a transaction (newly finalized block) while leaving the rest (partially confirmed blocks) open.
Furthermore, it is extremely challenging to construct queries that can read the state of the irreversible block while allowing new transactions to apply to the tip of the blockchain. The workarounds often significantly hamper the throughput of the database.
Techniques used by traditional databases to accelerate write performance via multi-threading result in non-determinism and are not suited for blockchains. This greatly limits the performance that can be extracted from traditional databases and makes their write benchmarks and parallel read benchmarks irrelevant for understanding the sequential read-modify-write performance access pattern required by all smart contract platforms I am aware of (except maybe UTXO-based blockchains).
Single Threaded Reading
EOSIO and Hive can only support single-threaded reading via the RPC interface because the underlying data structures cannot be modified while being read. We implemented various hacks on Hive that allowed multi-threaded reading at the expense of consistency and random crashes of the readers. I cannot speak to the current structure of Hive, but I can talk about experiences with RocksDB and LMDBX. While they allow multi-threaded reading, the overhead of versioning every record combined with other limits of their design means that overall throughput is significantly hampered.
Replicating State to Traditional Databases
At block.one we spent a lot of effort trying to find the best way to export the state from the eosio blockchain to a traditional database. The problem we faced was that it was difficult to keep up with the firehose of data coming out of EOS. Furthermore, we had to wait for a block to become final because replicating the fork-switching behavior through the entire stack was both fragile, complicated, and hurt performance.
Even if we could successfully and reliably replicate the database state to a database that supported horizontal read scaling the end result would be a centralized system and any applications built on it could be shut down unless every full node replicated the same complex setup.
There are several services that provide near-real-time indexing of EOSIO chains, but their databases are complex and expensive to operate and are not suitable for use by smart contracts. This limits their usefulness to powering interfaces for applications that subscribe to their APIs.
Time for a New Approach
Once our team set out to build a custom blockchain to host ƒractally, I knew that we needed a database technology that would perform well in RAM and gracefully scale to handle the long-tail of data that does not fit in RAM. It would have to do this without causing excessive wear on SSDs, which, on EOS, could cause SSD drives to fail in months instead of years.
For the past month I have been coding a custom database that is ideal for blockchain applications and today I am going to share some of the initial results. In a future post, I will describe the design that made these results possible. Note that benchmarks are not necessarily indicative of performance in real-world applications; however, they can compare the relative performance of different systems for the workload of a particular benchmark.
For this test I set up the "worst case" for a database, generating a random 8-byte key, and storing an 8-byte value. This test practically eliminates the ability to effectively cache the "hot keys/values" in RAM and is a good indication of worst-case performance. When it comes to accessing the long-tail of data that a blockchain may want to access it is practically guaranteed that such data will not be in the cache.
The Competitors (LMDBX and std::map)
As a point of comparison, I chose one of the highest-rated databases I could find (LMDBX) because it supported reading past states while advancing. Past experience with RocksDB and months of testing and optimization let me know that it would not serve us well. Some Ethereum implementations use LMDBX because of its performance over Rocks.
I also chose to compare against the default key/value store native to all C++ code, std::map. std::map isn't a proper "database" and only has to concern itself with maintaining a sorted tree of key/value pairs. It has no other overhead. Its performance starts out high, being in-memory, and eventually forces the operating system to start using virtual memory to swap to disk. At this point, we are simulating the upper limit of chainbase, which was used by Hive and is used by EOS. Chainbase has extra overhead and has historically always been slower than pure std::map.
The prototype ƒractally database is represented by three separate lines to compare single threaded random writes against writing while reading earlier revisions with 6 threads in parallel.
The Results
All databases have two levels of performance: one while everything fits in memory and another once the RAM resources are exhausted and it starts to go to disk. All tests were run on an Apple M1 Max laptop with 64GB of RAM. The variation in the disk-cliff point is based on decisions made by Mac OS on how to manage its page cache given the access pattern.
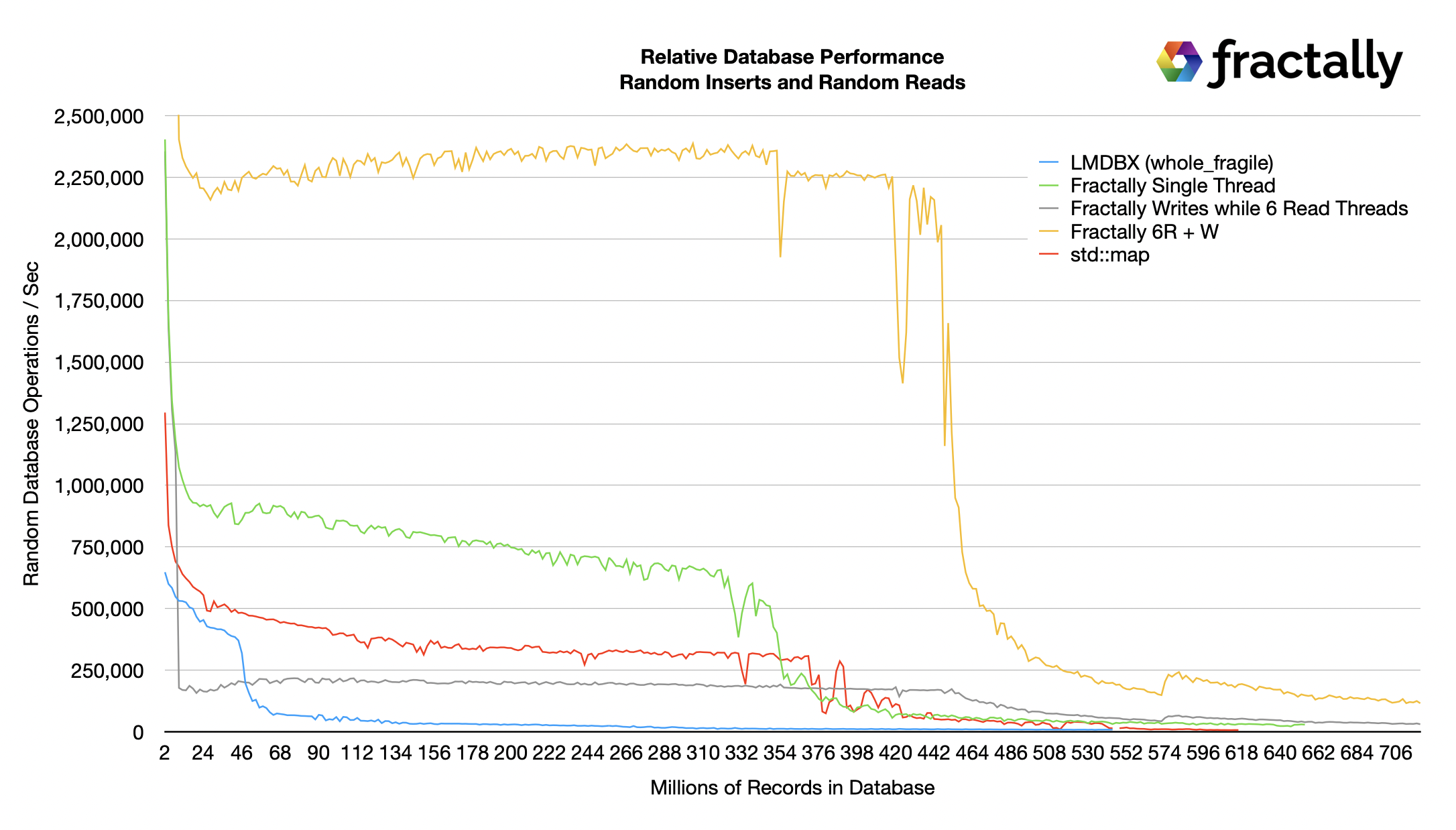
LMBDX gave up on keeping things in RAM and quickly fell to disk-based levels of performance even though it was configured to never flush things to disk unless the OS needed to swap pages. It may be possible to tune some LMDBX database parameters to keep more in the RAM cache and delay the drop in performance, but it would be a moot point given that it was well behind all other candidates even at its peak performance.
The Green line represents an apples-to-apples comparison of my new database's single-threaded insert against LMDBX and std::map. As you can see it is over 2x faster than LMDBX and std::map while everything is in RAM. We will zoom in on the disk-based performance in a later chart. This means it is likely more than 2x faster than chainbase as used in eosio and hive.
The Yellow line represents the combined performance of writing as fast as possible on one thread while doing random reads as fast as possible on 6 threads. Furthermore, the random reads are reading the state as of 4 "blocks" before the head block. This particular access pattern is not possible with std::map which cannot be read and modified at the same time and LMDBX made this kind of access too tricky to implement and their documentation suggests it would perform poorly. So any blockchain built on LMDBX would need a high-level caching system to support pending writes.
One of the consequences of having extra random queries is that write throughput drops. It is well known that RocksDB is not well suited to a heavy mixed load of queries and writes. The Gray Line represents the write operations occurring during the heavy query load.
Disk Performance
Because of the order-of-magnitude disparity between RAM and SSD performance, I have chosen to zoom in on the performance of the long tail as the database no longer fits in RAM. The first thing to observe is that LMDBX and std::map approach the same performance. I wasn't able to run LMDBX long enough to fill the database as far as the other tests because its performance dropped so much earlier.
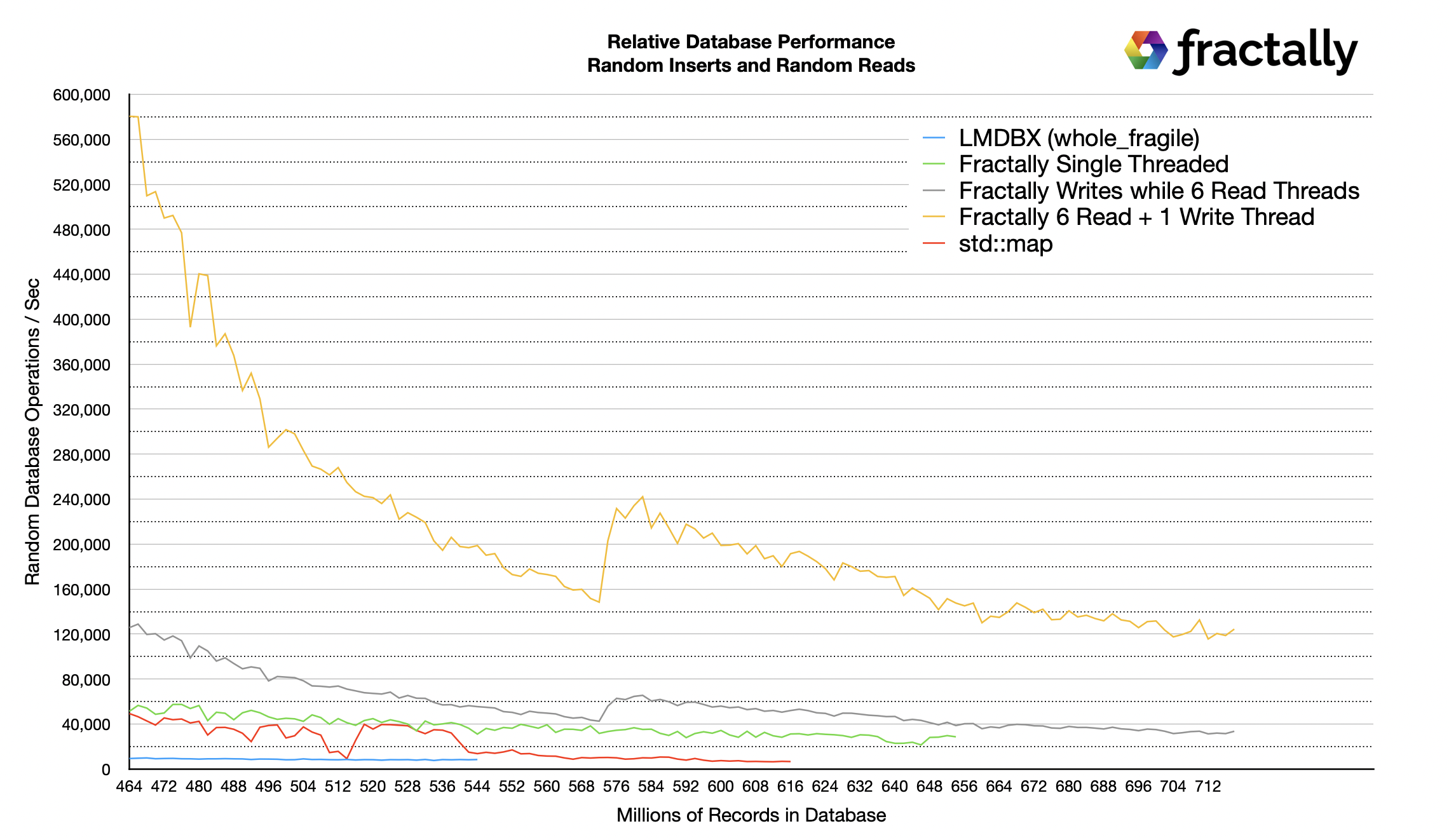
The next thing to notice is that the write throughput of my prototype database approaches the same long-term rate with or without read threads. However, the support for multi-threaded reading allows my database to sustain over 120,000 operations per second while performing over 30,000 random inserts per second while the state is larger than RAM.
Observing the disk activity using Mac OS X's Activity Monitor revealed that it was reading 900MB/sec in the multi-threaded read test and 300MB/sec read rate in the single-threaded write test. More importantly, for the sake of SSD lifespan, the writing activity was mostly zero with only periodic blips of 30mb/sec or less. This write activity was proportional to the actual rate of new data being added to the database.
Similar observations of LMDBX showed 50/50 Read/Write activity which would result in excessive SSD wear.
The Importance of Multi-Threaded Reading
One of the problems with accessing EOS' blockchain state directly from nodeos is that the majority of the CPU capacity is already being consumed just keeping up with the blockchain state changes. Furthermore, if you want to read only the "irreversible" or "final" state then you must operate a delayed node which compromises user experience.
The single-threaded access means that at most 50% of a CPU's capacity is available to service read requests and that API services would have to deploy a large number of expensive machines with a lot of RAM if they were to serve requests directly from nodeos. This is so expensive that no API providers go this route and instead data is exported to a more traditional database for query purposes. These service providers then become the centralized gatekeepers to the blockchain state. Note, that Ethereum has similar problems.
A blockchain-powered by my new database could potentially service 10x or more queries per second from the same state and would only be limited by CPU cores and SSD IO. The query performance may make it cheaper to simply replicate full nodes rather than move data into more traditional databases.
Furthermore, my new database allows long-running reads on thousands of different block state roots without hurting performance. This makes it possible to take live snapshots of the state.
Rocks DB vs Griffin DB on Ethereum
In my search for the best database technology I came across a study used to evaluate database options for Ethereum. This study plotted the performance of mixing random inserts with randomly reading data that already exists. This read-modify-write performance is critical for blockchain applications and gives an indication on how other databases perform.
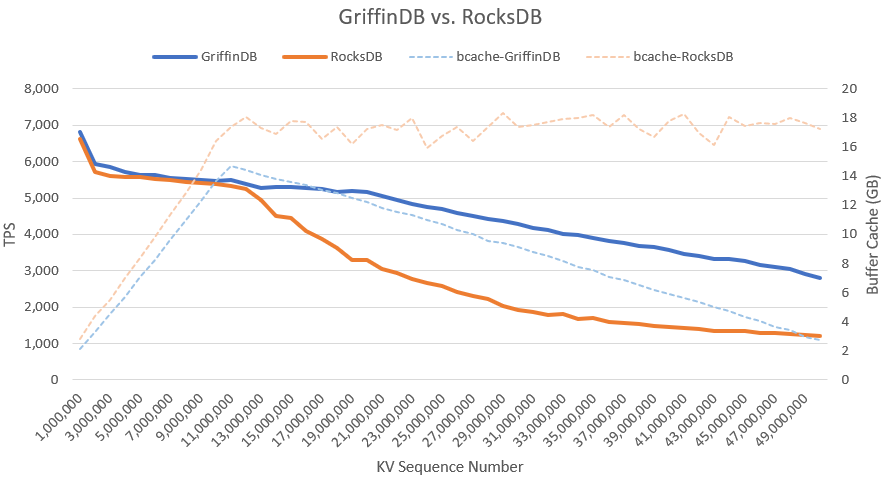
I decided to mimic this test by creating a simulated cryptocurrency with 25 million account names (taken from Reddit) and doing a transfer by reading two random balances and decrementing one while incrementing the other and then writing the change. In this test I could sustain 570,000 transfers per second, note that this level of performance was achieved because everything fit in RAM; however, it is still impressive because it is significantly higher than what std::map could achieve on similar data in RAM. Note: this test only factors in the database load and does not factor in the other overhead associated with a blockchain
Conclusions
Existing database structures are not well suited to the demands of blockchains and with this new database structure, our upcoming blockchain for fractally.com should be well-positioned to enable a more decentralized, scalable, cost-effective, and simplified infrastructure for developing the future of Web 3 and fractal governance. In the months ahead we will open-source this new database and reveal more about the design that makes it possible.
Disclaimer
Note that all numbers are based upon early tests and real-world performance may vary. There are many levels of a blockchain stack, including its virtual machine and smart contract libraries. All of these things combine to translate database "operations" into blockchain "transactions". A single "blockchain token transfer" requires at least two reads and two sequential writes. Experience shows that database performance tends to be the bottleneck once data no longer fits in RAM
I'm certainly far from a database expert but on first read this sounds like it is solving similar problems (or at least ends at the same place) as HAF, the Hive Application Framework, which @blocktrades and the core teams have been working on.
I'll be interested in hearing @blocktrades take on this. As usual, I always look a new, open source code like this with an optimistic hope that if it does something useful it can be folded in and used!
And it's good to see @dan back on Hive though it would be nice if you'd grace us with a profile image finally!
yup i thought the same.
Already solved :P
The cheese has multiple layers.
Sounds pretty solid if it works as you've described - excited to see the finished product. It sounds like other blockchains could potentially adopt it as well. It's probably worth noting that a good custom caching system for JSON-RPC requests from nodes is often highly valuable. For Steem we wrote a redis backed custom caching layer called Jussi, it probably is still part of the Hive stack today. The idea is that the vast majority of requests are for read only data involving irreversible blocks and therefor there isn't any need to ask the node for that data - if the custom caching layer is aware of what is irreversible and what is not then it can avoid hitting the nodes with unnecessary requests. For something like a social media site this is perfect and allows you to handle millions of requests per second with only a few nodes. You make a really good point about smart contracts, however, I imagine that a lot of requests from smart contracts are also read only and only executed by the node serving the request rather than needing to be executed by every node on the network - some of these types of requests could probably be served from a cache as well.
We actually talked about this same problem in our original whitepaper 2 years ago (wow time flies, lol) and our solution; StateDB/positive state deltas. Posted a new article about it here
Very nice! I had no doubt that the Koinos team already had an excellent plan in place and ready to execute on!
This is my hope as well. Constantly evaluating databases and seeing how poorly suited to the task they are gets old 😆 Lately, I've been convinced that caching is needed at the database layer itself and looking at systems similar to HAF that treat the blockchain as the source of truth for requests, but utilize a robust, populated system to index and serve requests. Hoping to see something from outcaste-io soon from their dgraph fork, outserv. Something from Dan would probably be far more efficient
p.s.
Totally using Jussi with Hive! Thanks for all your work <3
Besides the Hive Application Framework which was mentioned, one other major recent development here has been the One-Block Irreversibility protocol. Are you familiar with these developments?
Very impressive stats. Considering the human hours and budgets invested into database development over the years, such a performance boost would be an unusual and potentially revolutionary upgrade to database technology in general. Since the promise of true decentralisation requires distributed systems that allow every user to also be a 'full node' (or something similar), any moves towards lightening the processing costs of running nodes is very important and brings us closer to true human empowerment through the web.
I am looking forward to 'making SQL server irrelevant', along with 'making government irrelevant' ;)
But will it chug?
Thanks for using Hive, Dan!
Great work @dan. Always pushing innovations that lower the cost of blockchain adoption. Can't wait to witness the performance of fractally blockchain.
Wow! This is really exciting for projects like TUNZ which will have a huge lobrary of music nfts in it's inventory. Thanks for your continuous support for the blockchain.
Your content has been voted as a part of Encouragement program. Keep up the good work!
Use Ecency daily to boost your growth on platform!
Support Ecency
Vote for new Proposal
Delegate HP and earn more
Congratulations @dan! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s):
Your next target is to reach 25000 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
Support the HiveBuzz project. Vote for our proposal!
The rewards earned on this comment will go directly to the people(@seckorama) sharing the post on Twitter as long as they are registered with @poshtoken. Sign up at https://hiveposh.com.
RE Xthreading
this is how to fly... unless you enjoy being delayed at an airport
This looks like it will support the blockchain's blocks and irreversible block to me: https://www.postgresql.org/docs/14/sql-savepoint.html .. It just does it on disk not RAM so not very useful for a very high volume L1, but still useful to learn the technique and useful for each app where full nodes can provide additional APIs. I just checked, because it is in CockroachDb too, it looks like this can work atomically in a cluster (multiple databases) without needing to hire a full time database admin (as postgres might require): https://www.cockroachlabs.com/docs/stable/savepoint.html#savepoints-for-nested-transactions .. I have not verified this, on my radar though.