With the help of blue-green deployments, we have been able to progress our video recording infrastructure and product with zero downtime. This is possible because we keep two sets of servers running. One handles all incoming user connections while the other one sits idle, waiting for new application updates. Simplified, it looks something like this:
The Good
Running two sets of serves makes correcting mistakes easy. Pushed out some broken code? Run a swap command from your local machine and all new requests go to the old code on the green server set within a matter of seconds. Running some maintenance on servers is also a breeze. Run the necessary jobs on the inactive environment, then swap and run the maintenance on the other set of servers.
The Bad
As we continue to implement services with more distinct tasks, the need for servers running idle lessens. To spin up a notification service that runs cron jobs, we need to determine the active environment and get a distributed database lock to properly ensure the jobs are run by the newest code, and only by one server. Our transcoding service requires that we run some hefty compute-optimized instances, and in the inactive environment they sit there… burning money.
The Ugly
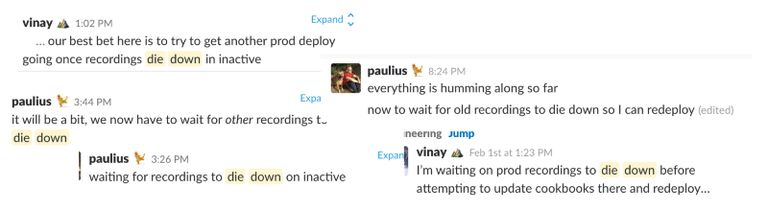
Our video infrastructure is all stream-based. Once a recording is started, a websocket is opened, the video stream is run through FFmpeg which writes the file to disk before uploading its chunks up to S3. This means we cannot close the connection and resume a recording on another server. This can mean hours of waiting and a bunch of these Slack messages:
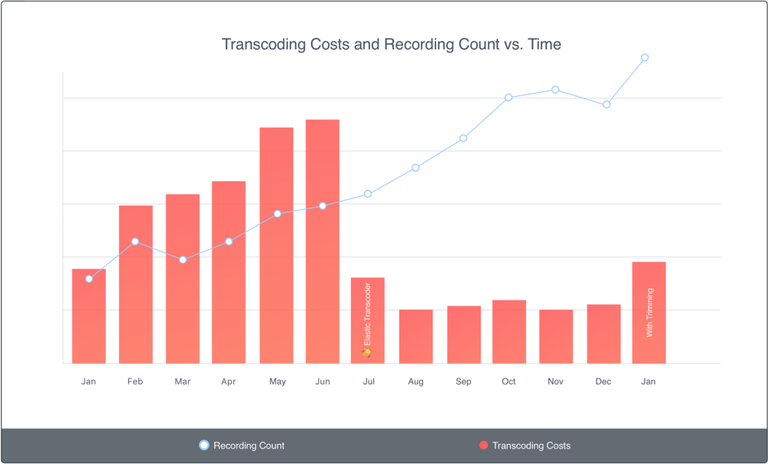
With the release of video trimming, which heavily relies on our transcoding servers, we have had to nearly double our transcoding capability. This made the cost of running servers in the inactive environment unacceptable costwise. To remedy this, we have been spinning down the newly active server sets after deploys had completed. This usually added about 20 mins of mental overhead to our production deploy process.
How Far Did it Get Us?
Far.
Twelve months ago our application and recording infrastructure ran, coupled, on Elastic Beanstalk (EB). We were plagued by stability issues: our recording service would take down our application service and vice versa. We were running FFmpeg through shared networks EBS drives which would get throttled. We didn’t have much insight into what was happening on our servers, EB obfuscated most of the information away, and we thought it should just work.
Even with all of those problems, we ran two EB environments and used blue-green deployments to reliably deploy and switch between them. At least that part wasn’t broken at the time 😄.
After our initial round of infrastructure and stability work, we moved away from Elastic Beanstalk to Opsworks and split out our recording servers away from the application boxes. We were dancing around in celebration when the recording service did not affect the serving of our application and vice versa 💃🕺.
No more bringing our laptops with us to social gatherings or the gym, no more of this:

We continued to use blue-green deployments after the latest infrastructure push. To cut costs even more, we spun up our own transcoding service and removed Elastic Transcoder, still using the blue-green deploy scheme. In the back of our heads, we knew that keeping a set of servers running idle in the inactive environment would not be sustainable from a cost perspective, but we have some product building to get to!
The Bad and Ugly Begin to Show
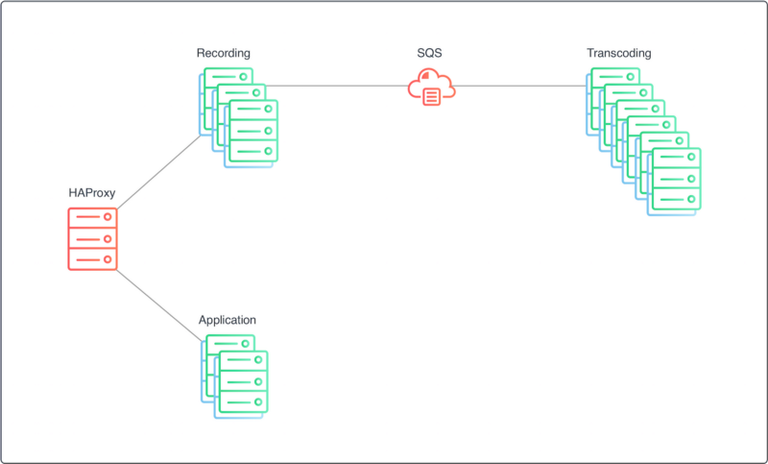
Over the next two quarters our users had doubled the amount of recordings going through our systems. As our traffic is fairly predictable, we were able to keep the costs relatively constant with the help of time-based autoscaling instances and some vigilance with our SQS queues.
With the introduction of video trimming, our transcoding servers are handling quite a few more jobs. Anytime a user edits his/her video, another job must be queued up and the video must be transcoded. To save costs, we started spinning servers down on the inactive environment manually until we finished moving away from blue-green deploys.
As our users continue to record and edit their videos on a daily basis, we want to avoid the headache of spinning more servers up and down manually, or occasionally forgetting to spin some down after a production deploy and letting that money go to waste.
The New Deployment Architecture
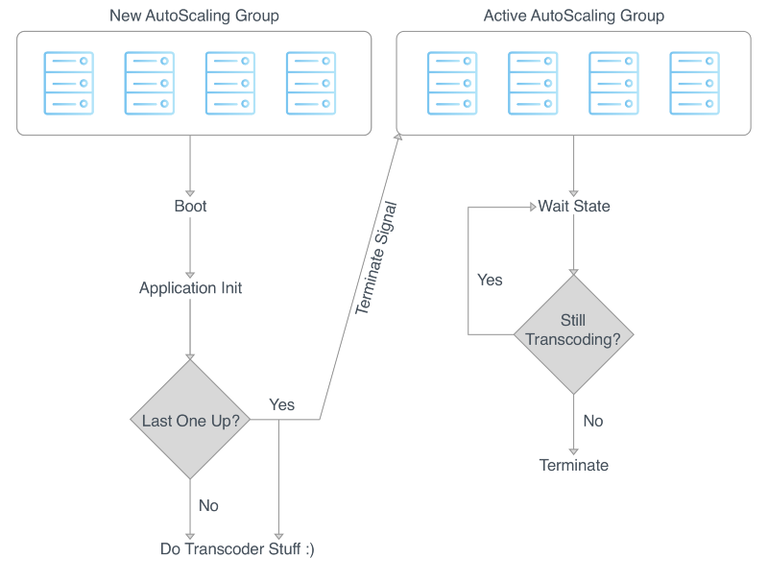
We now maintain one environment for our transcoding servers, rather than deploying to our inactive environment and swapping. Upon build completion we clone all existing instances into a new auto scaling group. As each new transcoder finishes booting and initializing it will try and ping all other transcoders in the autoscaling group. When the last server gets a 200 status from all the others in the same autoscaling group, it will signal the previous group to shut down.
The new sets of servers now transcode all incoming jobs while the old ones have entered a wait state || sad server purgatory o_0. Once they finish off their existing jobs, they signal the autoscaling group that they are ready to terminate safely. After running some cleanup tasks, the instances terminate.🎉.
Once we let this new new deployment scheme run in production and prove its stability, we will apply the same methodology to our recording and application servers (although due to the nature of our recording infrastructure, this will require a bit more fiddling) 😄.
We’ll be back on after we’ve tweaked this new deployment scheme and implemented it in other areas of our infrastructure✌.
Hi! I am a robot. I just upvoted you! I found similar content that readers might be interested in:
https://blog.useloom.com/why-loom-is-moving-away-from-blue-green-deploys-f038c0f6f65f
Congratulations @pdragunas! You received a personal award!
You can view your badges on your Steem Board and compare to others on the Steem Ranking
Do not miss the last post from @steemitboard:
Vote for @Steemitboard as a witness to get one more award and increased upvotes!