Link to corresponding reddit article here.
Yes you read the title right, I bought an NVIDIA TITAN V for BOINC.
Here’s what it looks like, courtesy of Anandtech (with older TITANs in the background):

Is it awesome? Yes. Am I crazy? Probably.
So I guess the first question would be: “Why?”
Well, to answer that question I think we should take a look at the specifications for one of these bad boys compared to the 1080 Ti it’ll be up against later in the article.
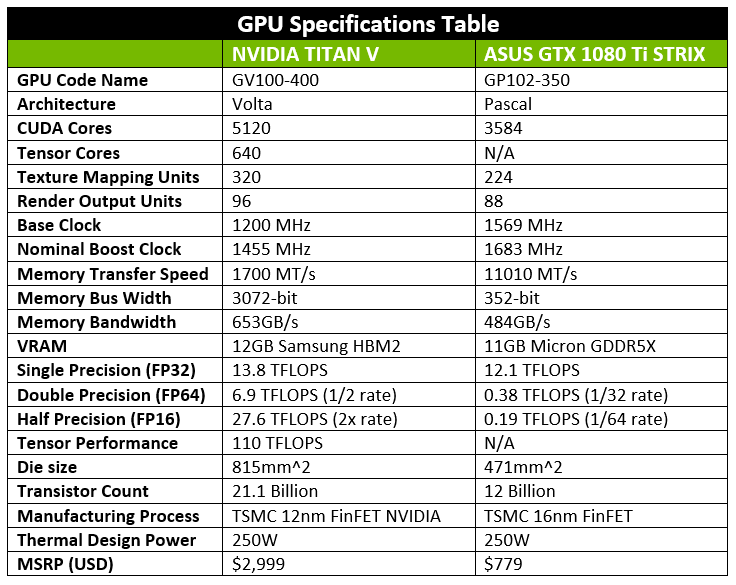
So the main reason I purchased the TITAN V for, was the ludicrous double precision compute power that’s displayed in this table. For reference, the R9 280X’s & HD 7970’s BOINC crunchers like to use for Milkyway only have roughly 1 TFLOP FP64! And obviously it’s no slouch at single precision either with its 5120 CUDA cores generating 13.8 TFLOPS. So despite the 250W TDP, the TITAN V actually has an interesting “maximum efficiency mode” that’s highlighted in the Tesla V100 datasheet.

Now obviously this is partially a marketing gimmick, and although this material is for the Tesla V100, both the TITAN V and Tesla V100 use the same GV100-400 GPU, hence it’s still relevant. So, after having used and monitored the TITAN, seeing this maximum efficiency mode at work is incredible with the phenomenal amount of compute power you still get at the significantly lower power draw that will be showcased later in the article.
Testing Setup
So let’s get to the meatier part of this, how well does the TITAN V perform in BOINC tasks? I’ll be putting it up against my 1080Ti in these tests to use as a measuring stick to see how well it performs relative to something known.
Here’s the full specs for my rig that’s being used for this testing:
| Component | Description |
|---|---|
| CPU | Intel i7-4790K overclocked to 4.6GHz |
| CPU Cooler | NZXT Kraken X62 |
| Memory | 2 x 8GB G.Skill TridentX DDR3 @ 2400MHz |
| Motherboard | ASUS Sabertooth Z87 |
| Storage | Samsung 850 EVO 1TB, 1 x 3TB WD Green & Black |
| GPU 1 | NVIDIA TITAN V |
| GPU 2 | ASUS GeForce GTX 1080 Ti STRIX OC |
| PSU | Corsair HX1000i |
| Case | Coolermaster MasterCase 5 Pro |
And here’s a picture of it if you'd like to see what it looks like.

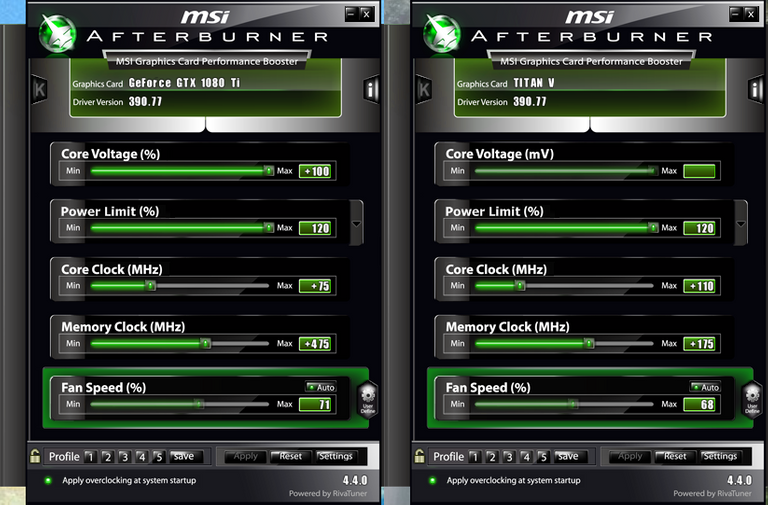
Testing was conducted at 29C ambient (damn Australian summer), and both GPUs were overclocked using the below settings in MSI Afterburner 4.40 using NVIDIA’s 390.77 driver.
Benchmarks
For this article I’ve tested Enigma, Primegrid (PPS-Sieve) and Collatz (Collatz Sieve) on both GPUs, and I’ve tested Milkyway on just the TITAN.
And for the results, I’m going to show an image of the BOINC Manager window which will show the completion time for the TITAN, and the relative progress of the task(s) running simultaneously on the 1080Ti, and also a screenshot of the HWiNFO64 monitoring program to show average power draw, temperatures and other statistics if you’re curious. In the BOINC screenshots, the upper task(s) are being run on the 1080Ti and the lower task(s) are being run on the TITAN. I’ll be using the average power draw in each screenshot to calculate magnitude per watt in the results table below this section. In addition, below each benchmark image I’ll provide some extra notes/analysis.
Primegrid
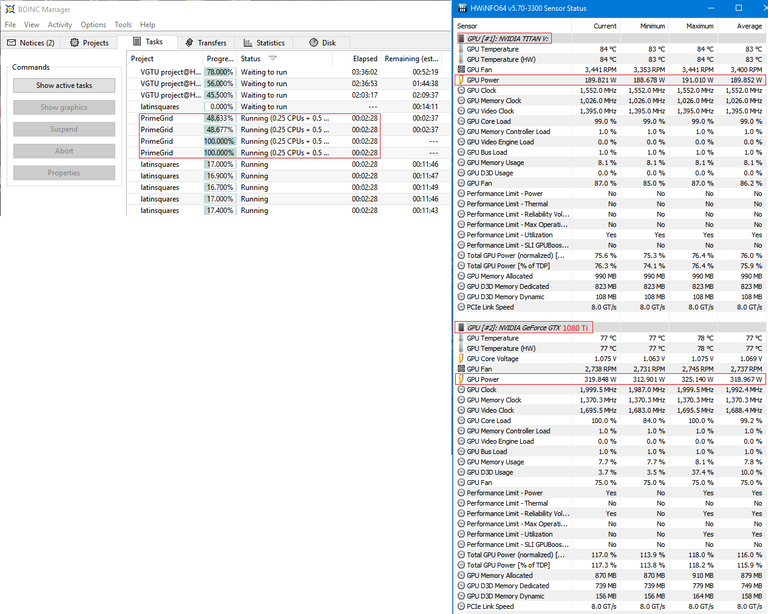
So Primegrid is probably the most intensive out of all the projects tested, and I’m using the app_config.xml file to run two work units in parallel for both GPUs. Immediately we can see the difference in efficiency between the TITAN and the 1080Ti, and also the pretty substantial performance difference. The TITAN completes the work units in just under half the time of the 1080Ti, and at just over half the power consumption.
Collatz
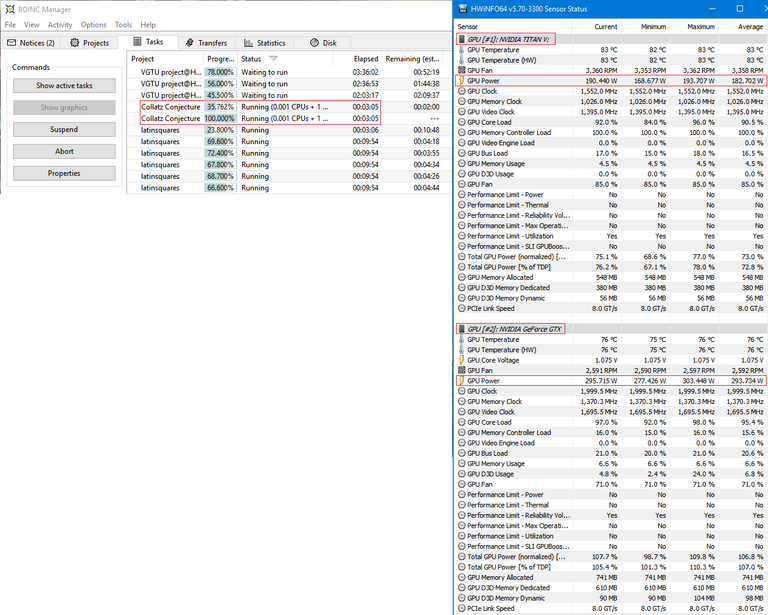
The story gets even worse for the 1080 Ti in Collatz, with the TITAN racing to finish at just over three minutes, while the 1080 Ti lagged behind significantly finishing at roughly 8 minutes and 30 seconds. It’s also worth noting that I did not perform any optimisations for Collatz, so these results are not indicative of optimised performance.
Milkyway
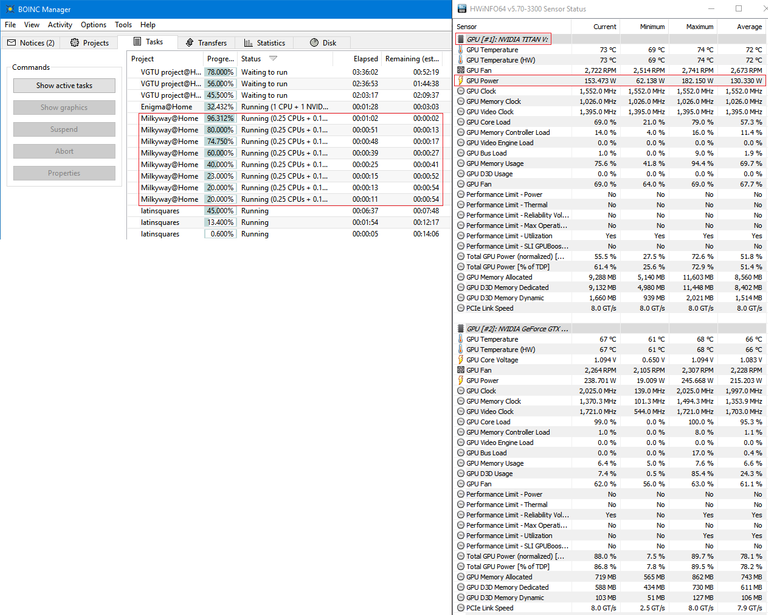
Milkyway’s work units don’t tend to finish in the same amount of time, so I’ll mention here that they roughly average out to 65 seconds per work unit. Here I’m running eight tasks in parallel, but I’ve staggered them. It’s pretty ridiculous how efficient the TITAN is at crunching these Milkyway tasks, only averaging 130W power draw for these eight tasks. There is also an important footnote regarding the TITAN and Milkyway I want to mention before the conclusion, so keep reading for that.
Enigma
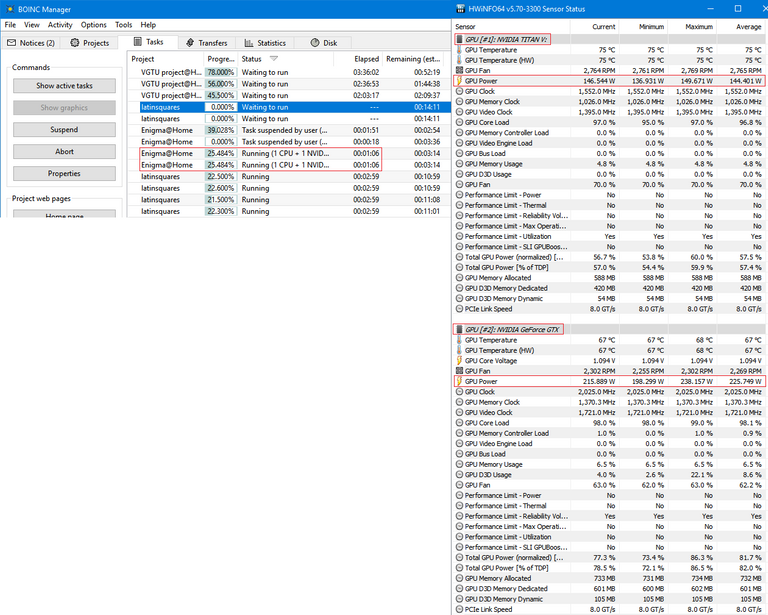
So since Engima uses a hill climbing algorithm, the time to completion cannot be accurately determined unless you average a large sample of results, so all I’m trying to show here is that the TITAN and 1080Ti are completely tied, and are being bottlenecked by something else. I imagine this would be the same for most of the other projects that aren’t as intensive as Collatz & Primegrid, so GPUGrid, Einstein, SETI etc. From my experience the Engima tasks usually take about 3 minutes and 30 seconds to complete on my 1080Ti.
Results
| TITAN V | Time to complete | Est. Max RAC | Est. Max Mag | Power Draw (W) | Mag/W |
|---|---|---|---|---|---|
| Primegrid | ~2:30 for 2 WUs | 3,883,392 | 162.98 | 190 | 0.858 |
| Collatz | ~3:00 for 1 WU | 18,075,144 | 175.68 | 183 | 0.960 |
| Milkyway | ~65s for 8 WUs | 2,416,541 | 177.54 | 130 | 1.365 |
| Enigma | ~3:30 for 1 WU | 1,814,400 | 56.81 | 144 | 0.394 |
| GTX 1080Ti | Time to complete | Est. Max RAC | Est. Max Mag | Power Draw (W) | Mag/W |
|---|---|---|---|---|---|
| Primegrid | ~5:00 for 2 WUs | 1,941,696 | 83.12 | 319 | 0.255 |
| Collatz | ~8:30 for 1 WU | 6,379,462 | 62.01 | 294 | 0.211 |
| Enigma | ~3:30 for 1 WU | 1,814,400 | 56.81 | 226 | 0.251 |
The estimated max RAC for each project was calculated as:
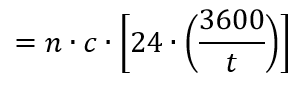
- n = number of WUs completed simultaneously
- c = credit per work unit
- t = time to completion for work unit(s) in seconds
The estimated max magnitude was calculated from multiplying mag/RAC by the above figure. Mag/RAC was calculated from analysing project statistics on gridcoinstats.eu’s website. These estimations are of course a rough approximation, and may not be entirely accurate.
A peculiar problem with the TITAN V for Milkyway
So before I get to the conclusion, there is an issue I’ve been having with the TITAN on Milkyway. The problem is, I can’t saturate all of the TITAN’s double precision compute using Milkyway tasks. So currently with 8 work units running simultaneously its GPU usage looks like this:
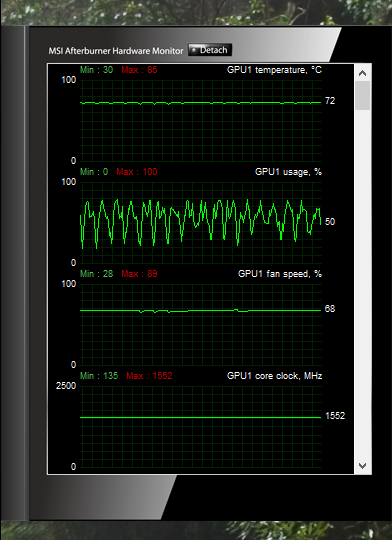
Obviously there’s still headroom for more work units right? We’re not at a consistent 100% usage. The problem is, each work unit uses approximately 1.5GB of VRAM, and if any work unit tries to allocate more than the 12GB of VRAM on the TITAN, all the work units error out. So effectively I’m capped at using 8 work units simultaneously unless I can somehow reduce the VRAM usage per task. At eight work units, this is what the GPU memory allocation graph looks like (Y-Axis is memory allocated from 0 to 12500 MB):
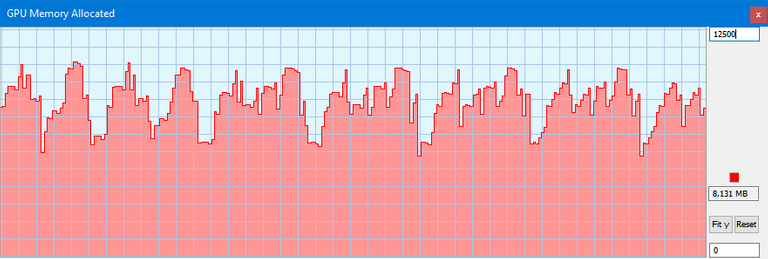
This is where you, dear reader, come in: if you know how to manipulate the app_config file or some other Milkyway setting to reduce VRAM usage, please let me know so I can push the TITAN to its full potential.
Conclusion
Despite the fact that the TITAN’s single precision compute is only theoretically 10 – 15% ahead of the 1080 Ti, it seems to perform significantly better than the 1080 Ti in heavier single precision applications, like Primegrid and Collatz. It’s also remarkably more efficient, providing three or more times more magnitude per watt than the 1080 Ti. The project I’m going to use for the TITAN is probably going to be Milkyway, with Primegrid as a backup since Milkyway has been having a lot of database and other server issues lately. So, if you guys want me to benchmark the TITAN on another project, feel free to ask in the comments below, or if you’ve got any other questions I’m happy to answer. Thanks for reading!
Good stuff wouldnt have tested it myself at that price. :p
A couple of questions for helping with calculating hardware performance tables:
Is there a way to know how many work units you should be running at the same time for a given project (other than as many as it takes for full GPU usage)?
Does running multiple tasks on a GPU slow down the individual tasks?
I try to max-out the GPU usage.
As I only have mid-range GPUs, it's always only one task per GPU.
They are then at 95-100%.
You can use two tasks per GPU to get the time between ending and starting a new task not wasted but I think this results only in some single percent in total.
Your GPU can run as many tasks simultaneously as they fit in its VRAM.
It doesn't make a difference in running one or multiple.
If one task alone needs 1min and already uses 100% of the GPU, then by using 5 tasks, one needs 5min.
In the other way, if this one task uses only 20%, then by using 5 tasks, your GPU gets the wanted 100%.
Honestly it's a long time ago I've tried multiple GPU-Tasks but from the logical side this should be the behavior... :)
No I don't have a super accurate way for determining how many work units I should run simulanteously, other than looking at GPU usage and trying to max it out, and then just comparing how many work units I'm outputting per unit of time. So for example, I did a quick test for PrimeGrid, with only 1 task per GPU to see what the difference is:
TITAN V
1 task - 1:50 per WU
2 tasks - 2:30 per WU
1080 Ti
1 task - 3:20 per WU
2 tasks - 5:00 per WU
So you can see here, running two tasks in parallel on the TITAN would end up producing equivalently 1 WU per 75 seconds, whereas if I was running one task at a time, I'd be producing 1 WU per 110 seconds. So yes, running multiple tasks does slow down the individual tasks, but overall you get more output, if GPU usage wasn't maxed out already.
Great research!
While on paper they have almost the same single precision FLOPS count, Titan V can do even 3 times better in real world applications.
Due to purchase price difference, it seems only Collatz and Milyway are projects where running Titan V is cost optimal vs running GTX 1080 Ti and cost might be close at PrimeGrid.
Are you going to test them on Amicable and Einstein maybe?
I believe it might be down to a difference in the way GV100 is designed at a fundamental level. To quote this anandtech article:
So this seems to make it perform better with integer-type (Primegrid/Collatz?) compute applications. Anyway that's just my speculation.
Yeah pretty much thanks to the price tag, I'm gunna keep it crunching more earnings-focused projects for now. Although I prefer crunching Primegrid over Collatz personally since I like Primegrid's objective more. I'll write a followup article with some more benchmarks, I'll be sure to include Amicable and Einstein.
If you're done testing it and don't need it anymore or if you need more space and want to get rid of your older titans .. i could take care of them for you ;)
The photo I used at the top isn't mine, I took it from this anandtech article, I wish I had that many titans lying around.
Amazing. So jealous.
Could you use the excess computing power for foldingcoin/curecoin while mining milkyway?
Also, would you be able to fiddle with the settings on the Edit MilkyWay@Home preferences page?
There is the setting :"Frequency (in Hz) that should try to complete individual work chunks. Higher numbers may run slower but will provide a more responsive system. Lower may be faster but more laggy." which may force a higher intensity.
You may also be able to reduce the CPU allocated to milkyway down to 0.05 or 0.1 in your app_config.xml for each task.
I've tried the Frequency setting, it doesn't seem to impact VRAM usage unfortunately. Changing the CPU allocation factor also wouldn't do anything, that just changes the amount of CPU time the BOINC Manager thinks a work unit uses, not what it actually uses.
I'm worried about possibly crashing the NVIDIA drivers if I tried to run multiple different compute applications at one time, so I don't think I'll try to crunch foldingcoin/curecoin simulanteously.
Man, such a waste, dont use it on windows, you need to use it on linux so you can run it on cli only mode, the perfomance difference is usually around 15%! Or at least dont use it as display, but in that case you could still gain a few % since these apps are built for linux and then ported.
I don't run my display off the TITAN, I use the 1080 Ti for that because I game on the 1080 Ti. I'm also pretty unfamiliar with Linux in command line only mode. I also don't know if I'd be able to overclock my GPUs on Linux CLI-only. So yeah, I'll be sticking with Windows even though I might be losing some performance.
O, you could just set it up in a graphic enviroment and then swap out to a tty pressing ctrl+alt+f(1-7)
Is there any data backing up the claim that Linux is faster for BOINC than Windows? I've heard it repeated, but I've never actually seen any data.
Yes.
There is the simple fact that linux has been much more optimized for scientific tasks than windows, its free, you can modify it, and it runs in 99-98% of all supercomputers. Of course there is going to be more work towards that.
then there is the fact that windows has much more tasks to do when idle (not really that important for gpu computing).
Last but not least, there are some applications such as TN-grid that just dont run natively on windows or run very slow and have to use mingw, which brings the linux family of oses way of interacting with programs to windows, and its slower than doing it natively on linux, obviously.
If you have any numbers to share of actual performance comparisons I would be interested.
I hope milkyway steps up their game and tries to optimize their tasks for titan v, there is some great potential there
Wow, that's seriously impressive double precision performance! That thing will destroy milkyway@home work units! :D