Automation to the Rescue!
This Python 3.6 script uses the Steem Beem Library and a variety of methods to archive your Steem Blog images as well as markdown files. It used image hash verification to ensure that files are downloaded once saving valuable storage space.
Repository
https://github.com/anthonyadavisii/SteemYaLater
Version 2.0 Change Notes
- Added PyCurl download method to address issues w steemitboard images
- Data Deplication enabled: Prevents redownload of file if already exists in folder structure. Symbolic link with relative path placed instead saving valuable storage space.
- Logging and CSV output: Session log file is produced in working directory. Output CSVs are created for each account so users may readily see what failed and may require manual action.
Version 1.0
Version 1 was the basic framework with wget. We don't talk about version 1 anymore.

I've worked hard and made a ton of progress in order to give my fellow Steemians a way to save their priceless data.
Roadmap
- Steem Blog Backup as a Service
- @dtube thumbnail support
- Upload to Skynet web portal
Known Issues
DTube thumbnails will not download as they are not stored within the Beem Comment json_metadata image property. Logic to be added to accomodate. Also, some links may require escape characters. These will be addressed as time permits.
Uses Python 3.6
Install Prerequisites
# PyCurl may require the following packages be installed.
sudo apt install libcurl4-openssl-dev libssl-dev
# Python modules installation
Python 3.6 -m pip install beem
Python 3.6 -m pip install wget
Python 3.6 -m pip install urllib3[secure]
Python 3.6 -m pip install pycurl
Python 3.6 -m pip install certifi #may or may not be needed if the [secure] option is used for urllib3
Execute Script
python3.6 SteemYaLater.py
Prompts for Steem User. Alternatively, you may populate the accounts list variable with users to backup
Account to Backup? anthonyadavisii
Script will crawl your blog_entries filtering out resteems (reblogs)
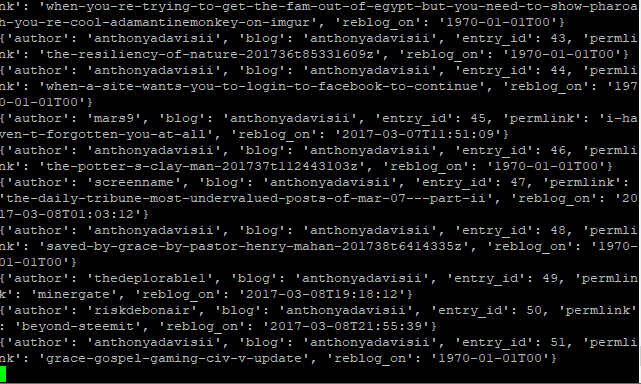
Will then cycle through each blog_entry, save the body to a .txt files, and grab any images it can with wget or urllib3
Feel free to reach out if you need help! If you appreciate the work, consider sending me a tip!
How to put your FREE Downvotes to work in 2 easy steps!
This post was created using the @eSteem Desktop Surfer App.
They also have a referral program that promotes users to onboard to our great chain. Sign up using my referral link to help support my efforts to improve the Steem blockchain.
Ditch Partiko and get eSteem today!
| PlayStore - Android | Windows, Mac, Linux |
|---|---|
 |
 |
| AppStore - iOS | Web |
 |
 |
There are errors in your install prerequisites
Python 3.6should bepython3.6Also, I had a problem installing pycurl, so do this first:
sudo apt install libcurl4-openssl-dev libssl-devthen
python3.6 -m pip install pycurlAnother problem when I run it:
FileNotFoundError: [Errno 2] No such file or directory: '/home/drak/SteemYaLater/Backups/drakos'So I created that folder manually, then I run the tool again, it fetches the posts but when it starts downloading them, it spits out binary characters on the screen. Did you test this tool properly?
I forgot about that. Yes, that was also encountered during my setup but it slipped my mind. I'll update the readme. Thanks, @drakos!
Terminal is spitting out garbage but it's backing up some of my posts at least after I made the backup folder.
Good catch! Updated repo
https://github.com/anthonyadavisii/SteemYaLater/commit/172a3883a29b40fed8b70d5124e6293e66084439
My man! For those who didn't know, he's been working diligently on this for a while now. He deserves more than the 125 upvotes I'm seeing right now.
Amazing work, thank you
Really appreciate coming up with this! Going to test now.
May want to get the latest as I made a few tweaks and addressed a couple issues.
I ran into some delimiter issues/erros while trying to run. I have raised an issue. Will check whether I can fix (Im stuck with this bloody Bitcoin and ZMQ crash at work!)
Can you set it up to email pdf's?
Or provide a link to download a PDF?
What I'm doing currently is zipping up the backup on my Ubuntu box, transferring that to my cloud provider, and then providing a shareable link.
It's a few too many manual steps at the moment but plan to automate some of the steps such as having the script take care of compression. You're update should be next up btw
Sweet, I would hate to be wiped from the only history likely to be written by me.
I'm not going to try this in current form due to an adversion to the technical nature, but I do like the road map.
Your efforts are greatly appreciated.
I look into putting all the dependencies into a docker container to simplify use and so users on non Ubuntu operating systems can use. Thanks for the sentiment. Glad to help!
I'm running linux minty on a netbook I rarely use...would that manage this?
Unfortunately, the newest version from Github does not work. Any chances to fix that?
File "SteemYaLater.py", line 187 continue ^ SyntaxError: 'continue' not properly in loopThanks for the heads up. Will take a look.
Let me know when it's ready, I would love to contribute by dockerizing it.
Removed those continue statements. Should be good to go now. Putting it in docker would be really helpful. Thanks!
Thanks, I will do a PR tomorrow.
@dexterdev
Thank you @mathowl
@scienceblocks see this. maybe of help to you
Updated again to inject header data to steemitimages.com. Recommend increasing pauseTimeInit due to suspected rate limiting.
Finally!
Thanks Bro!
@tipu curate
NP. Just added another check on image hosts for DNS lookups. Ideally, I'll store unresolved hosts in memory and skip them if they were not resolved previously. Due to the pyCurl settings, the script tends to get hung up for a while on timeouts. It works but definitely more optimization needed.
Appreciate the reblog. Hoping to have a full-fledged service up soon but need to work out my storage solution atm.
Congratulations @anthonyadavisii! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Do not miss the last post from @steemitboard:
Vote for @Steemitboard as a witness to get one more award and increased upvotes!
Cool