Preface: This post describes the work done in the past week or so by the BlockTrades team on hive-related software. Since it's essentially a progress report for other devs, it presupposes that the reader is familiar with the ongoing work. In other words, it assumes you've read our sixth month roadmap and the previous progress reports. Reading these posts has also been likened to watching paint dry, so be warned :-)
Overview of the week's work
A lot of the coding work done this week was cleanup work, as we want to make it easier for new devs to contribute to the code base.
To that end, we’ve once again ramped up our work on creating tests, removing dead code that might confuse new programmers, and investigating methods of documenting the code and the APIs.
For the latter issue, we’ve decided to use OpenAPI as our preferred means for documenting API methods so that documentation web pages can directly be generated from annotations in the source code itself. By establishing a direct linkage between the API call and the code that implements it, it will be easier to know when a particular API call hasn’t yet been documented. I think this also implies that we will need to create a task to migrate a lot of the existing external documentation into the hivemind codebase.
In addition to the above, we also continued our work on creating the modular hivemind framework for 2nd layer apps.
Hived work (blockchain node software)
During testing, we found that the initial version of the code for directly filling hivemind’s postgres database from hived had several problems (a problem with thread cleanup and some performance issues with queries that insert data into the database), but these were resolved, and the performance tests are looking good so far, but we haven’t done a full test yet on the latest code.
We’ve also found some additional information that we need to inject into the database (some of the data that hivemind currently pulls from hived using get_dynamic_properties api call). We should be ready to perform another sync test for this code in the next day or so. This work is going on here:
https://gitlab.syncad.com/hive/hive/-/commits/km_live_postgres_dump/
The code for tracking the last governance vote for an account was completed here:
https://gitlab.syncad.com/hive/hive/-/merge_requests/160
This code will be used to compute when governance votes will expire as part of hardfork 25.
Tests were written to test changes in cli_wallet:
https://gitlab.syncad.com/hive/hive/-/merge_requests/163
code cleanup (removing unused/dead code):
https://gitlab.syncad.com/hive/hive/-/merge_requests/77
We also completed our performance tests of the BlockTrades-contributed source code changes to hived that generate additional virtual operations for accounting computations (we wrote this code a long time ago to help us compute our blockchain-related income). As I anticipated, there were no significant impacts on either computation performance or account history storage requirements, so we’ll be merging in these changes in the coming week. I think these results also validate to some extent my plan to continue to use virtual operations as the primary way to pass internal state information from hived to hivemind.
Hivemind (2nd layer microservice for social media apps)
Below is a list of some of the changes we made to hivemind this week:
Optimized a few more API calls by reducing amount of work required of the SQL query planner:
https://gitlab.syncad.com/hive/hivemind/-/merge_requests/459
Added threads to speed up post-"initial sync" operations needed by hivemind indexer (e.g. creating table indexes):
https://gitlab.syncad.com/hive/hivemind/-/merge_requests/446
Community functionality moved from python to SQL to enhance performance and ease future maintenance:
https://gitlab.syncad.com/hive/hivemind/-/merge_requests/451
Several reported issues with notifications were fixed in this MR:
https://gitlab.syncad.com/hive/hivemind/-/merge_requests/461
tests
https://gitlab.syncad.com/hive/tests_api/-/merge_requests/225
https://gitlab.syncad.com/hive/tests_api/-/merge_requests/228
https://gitlab.syncad.com/hive/tests_api/-/merge_requests/221 (tests for community apis)
https://gitlab.syncad.com/hive/tests_api/-/merge_requests/224 (full sync tests for community apis)
https://gitlab.syncad.com/hive/tests_api/-/merge_requests/227
code cleanup (removing unused/dead code + code reformatting):
https://gitlab.syncad.com/hive/hivemind/-/merge_requests/436
https://gitlab.syncad.com/hive/hivemind/-/merge_requests/465
Condenser and wallet (https://hive.blog)
Improvements to build process for condenser and wallet:
https://gitlab.syncad.com/hive/condenser/-/merge_requests/189
https://gitlab.syncad.com/hive/wallet/-/merge_requests/92
Fix bugs reported when showing profiles of some older accounts by using post_json_metadata:
https://gitlab.syncad.com/hive/wallet/-/merge_requests/93
Fix a problem with display of hivefest badge:
https://gitlab.syncad.com/hive/condenser/-/merge_requests/191
Near-term work plans and work in progress
On the hived side, we continue to work on the governance changes discussed in our six-month roadmap post.
We’ll also be reviewing the state of the SMT code in the coming week, to get a feeling for how complete it is in terms of functionality, etc.
On the hivemind side, we’ll continue work on tests and documentation.
We’ll also be continuing our work on modular hivemind, with the current focus on the hived plugin for this and on experiments for modifying hivemind’s indexer code to work from the new tables created by the hived plugin.
The work you are doing has me excited for Hive again. I will be honest, seeing how long it has been since we first heard of SMT's prior to the Hive fork and still not seeing them released, it has been a drag in the progress department.
Knowing that Steem did a lot of the code at a time when they were laying their best developers off and focusing on austerity measures, I don't blame you for being cautious. When Dan Larimer left, the quality of the code and release process went downhill dramatically. It's nice to see some proper management and competence again.
I know the community stepped up with the likes of Hive Engine creating their own layer solution, but it's not the same as a native and better performing solution. I am perhaps most excited about the second layer solution you are working on. Using custom JSON solutions and streaming the chain works, but it's a process fraught with numerous issues and complexities (which you've already outlined in the roadmap) that even the most experienced of devs in this community inevitably encounter.
I foresee the community rallying behind an official and modular layer system that pairs nicely with the creation of custom tokens. Games through to fully blown decentralised exchanges and everything else in between.
I am excited again.
@blocktrades you are a machine!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Not being a dev or programmer in any respect, just a user, I am happy to see that if/when people decide to limit the amount of time for witness votes to stand that you have the mechanism ready to roll out. This should be a big help on finishing a solid first layer foundation.
Of course most of the work is way above my level of understanding, but I do still enjoy reading the reports.
I am excited to hear what shape the SMT code is in. I have low expectations, so maybe I will be pleasantly surprised. Even if most of it is unusable, at least you will now know that so you can start planning future work.
Thanks for the update. Good stuff.
Thanks because you, i can be know about it
I am looking forward to governance decay. Can't wait to see if the top 20 are shaken up after the switch.
Thanks for all that you do for Hive.
!beerlover
Congratulations @blocktrades! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
Wow. Check out my follow list! Says I'm not following anyone. It got wiped out! Don't know if it was due to a blacklisting I did or not. Had an advisory message about blacklisting saying I had to accept the hive.blog blacklist, and that was that. Didn't notice that I wasn't following anyone until I went to "Friends" though, which was later. Could be a bug? Is this the first time you've heard of something like this? When looking at hiveblocks I see nothing, but then again, I don't know if an "unfollow" would show up . . . thinking that it would.
Thanks. https://hive.blog/@cryptographic
EDIT: Sorry, I do see something on hiveblocks. Screenshot below where I seemed to have followed an account named @all
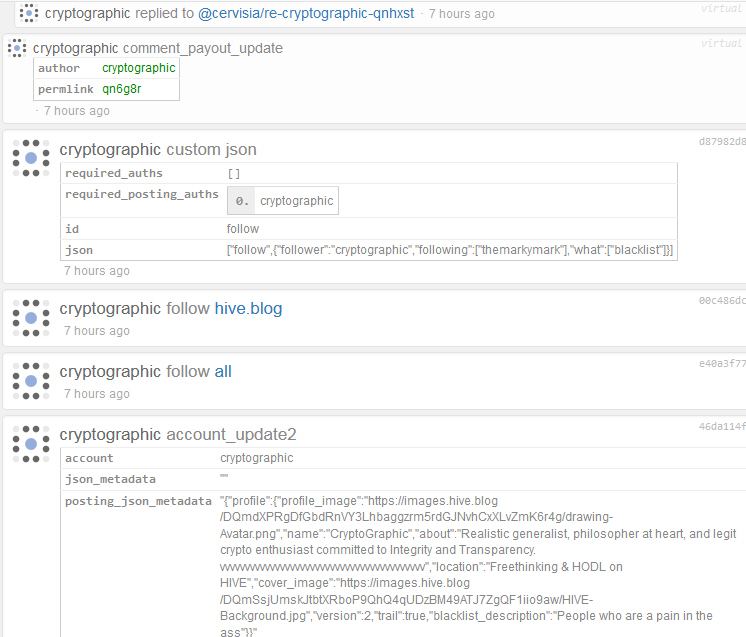
There's a known bug in hivemind that causes this and I raised the issue with our devs last week. Your follow list isn't really lost, it's just hivemind is interpreting the data improperly right now. I actually had a meeting scheduled today where I was going to check on the status of this issue, but the meeting got canceled due to sickness (not mine, I'm fine). Anyways, I should be able to get an update on the situation tomorrow. In the meantime, rest assured it's a temporary problem and none of your info is permanently lost.
No problem. Glad to hear it's a known issue. No hurries either. It'll happen when it happens. I can navigate around manually for the time being. Thanks!
Edit: Out of curiosity, that account @all ???
????????? Jesus
Sorry to bother you with this again, but I wanted to ask if you're still confident the data isn't lost - I could always start rebuilding manually, but I'd hate to find out later that I had wasted my time (due to a possible automatic "restore" of the data after a manual rebuild, which would take a good deal of time since it's a one-by-one process).
I don't believe the data is lost. It was discussed in dev meeting today, but the short version is we're reviewing and testing the changes now. If everything goes well, the fix should be deployed sometime this week.
We've finally been able to deploy the code for hivemind with the follow fixes. Can you checking using hive.blog to see if the follows for your account seem correct now. Note this will currently only work if using api.hive.blog as the fixes haven't yet been deployed on other api nodes until we've done sufficient real-world testing.
Still "Not following anybody". ;-(
Are blacklists functioning yet?
The dev who is responsible for approving the changes and merging them in is out sick right now, so not yet. I expect the fixes will be merged in and we'll complete testing in a few days, assuming no problems are found during code review.
It is a very good sign that we are being given update on weekly basis. Thanks for information