HiveSense - Why nothing worked at first (And what we did about it)
I have already written a post about HiveSense. Today, I would like to share what our first month in this project looked like - our assumptions, decisions and challenges.
Why did we start working on HiveSense? We wanted to prepare something special for Hive's birthday.
We considered different ideas for using AI on Hive, and finally we decided to build a tool that helps Hivers search for interesting posts and use AI for it. We had one month.
This post describes the first month of working on this project. The project is now more advanced and new challenges lie ahead for the developers. You can find more information about it here: https://gitlab.syncad.com/hive/hivesense .

General assumptions:
Posts on Hive are written using words ;). But all computers need numbers. So the first thing we did was translate the posts into a language understood by computers. We used an AI model to convert the posts into embedding vectors.
The embedding vector is a way of representing text as a sequence of numbers (a vector) that a computer can easily analyze in terms of meaning. Texts with similar meanings are mapped to vectors that are mathematically close to each other in space.
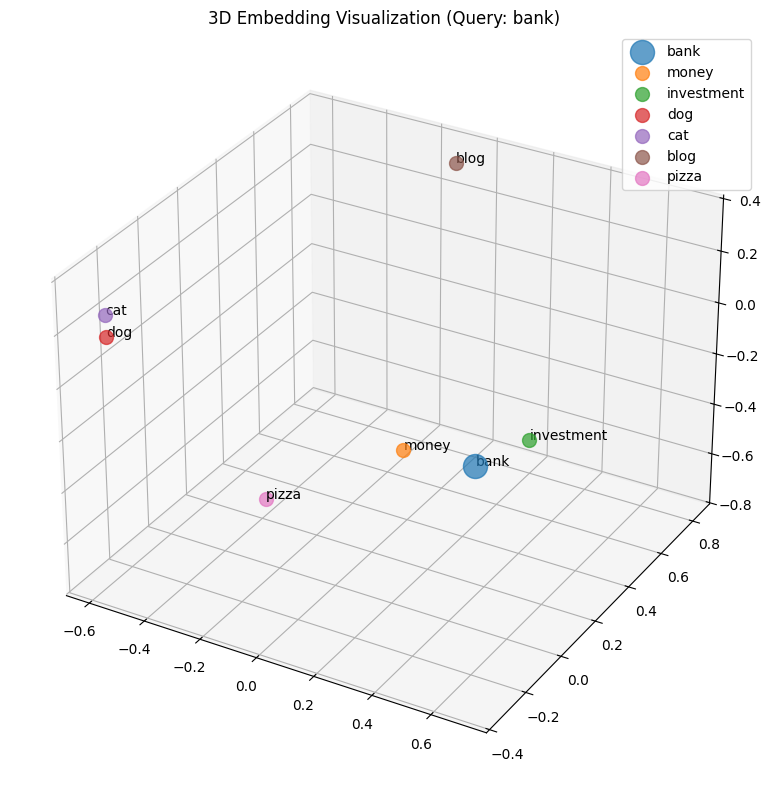
Embeddings are stored in N-dimensional spaces where N is usually between 50 and 200. That means each word is represented by a vector containing 50, 100, or even 200 values that tells us where it lies in this N-dimensional space and what its closest neighbors are - basically what's the meaning of this word. Example above shows what embeddings look like in 3 dimensional space. Words like “money” and “investment” are relatively close to “bank”.
There are about 14 million blog posts on Hive. For each post, one vector was supposed to be calculated (spoiler: that turned out not to be true) and stored. The problem: a lot of computation and a lot of data to store.
The posts are written in different languages, so the Large Language Model (LLM) should support many of them.
Users should be able to easily find what they are looking for, and it should work quickly. The system also has to be fast enough to handle many searches per second.
Technical decisions made
1. What database should we use?
The real question was whether we should use a specialized database designed for calculating and storing embedding vectors, or if PostgreSQL would be good enough. We decided to use PostgreSQL, because we are familiar with it. We also use HAF with Hivemind, since all posts and comments are already collected by Hivemind.
We use two PostgreSQL extensions:
- pgai - an open-source extension that allows execution of AI tasks without using external infrastructure
- pgvector - an extension that allows storing and searching vector data such as embeddings generated by LLMs.
2. What should we use to work easily with LLMs?
We decided to use Ollama. Ollama makes it easy to run LLMs (Large Language Models) by providing a simple REST API to work with. It requires very little setup and supports GGUF models (GGUF is a file format used for storing and running language models).
Each server runs independently, so it can be easily scaled. Moreover, it supports many available LLMs.
HiveSense sends to Ollama two types of requests:
- For newly created posts - a request is sent with the post body to compute embeddings,
- For searching - a request is sent with the search phrase to compute embeddings.
3. Which LLM should we use?
There are many LLM available, but not many of them support multiple languages. We decided to use yxchia/multilingual-e5-base:F16. It allows for fast and effective embedding generation for many languages (nearly 100). This model is optimized for semantic search.
Performance was crucial - with wider vectors, the results are better, but they take up more space in the database and slow down embedding computation. So we also had to find a compromise between quality, storage space and processing time.
The first challenge - embedding calculation was extremely slow
There are 14 million posts and it looks like calculating embeddings for them takes weeks - it is not acceptable!
We were unsure whether the PostgreSQL database was good for this purpose.
We could observe that Ollama wasn’t using all its GPU (in our case the GPU was about 10 times faster than CPU). But the real problem was that we were sending requests too slowly. We used the pgai extension and it turned out that it is not prepared to serve so much data. We made some improvements - instead of sending post by post, we started to send a batch of posts and received a batch of calculated embeddings.
And it started to work! It took just 24 hours to calculate embeddings for 14 million posts!
The second challenge - this is not what we expected to find
It didn’t work. At all. If you entered a phrase like: “Thailand, boat on the beach”, it showed you Thailand, but not the boat or the beach.
Short posts were matched too easily
It turned out that when the posts were short (like Activefit report cards), they matched very easily and with unsatisfactory accuracy. Why? Because the embedding of a whole sentence or article is weighted by the embedding of its words. The longer the article is, the more weighted the embedding becomes and distance from simple words is longer.
For short sentences e.g.. “beach in Thailand” the embedding is weighted by just two words so it ends up very close to both “beach” and “Thailand”. For the whole article about beaches in Thailand, the embedding tends to be more distant, because the author might also write about food, people and fauna. That’s why articles with just a few sentences became biased, even though they might not provide as much relevant information compared to longer articles.
That’s why we decided to filter out posts shorter than 50 words. And then also removed emotes, tags and links, because it disrupted the calculator of embeddings.
However, the results were still unsatisfactory.
One post, one embedding - not a good assumption
There are surprisingly many long posts on Hive and calculating single embedding for such posts disrupts the search results. The longer the post is, the more diverse topics it contains, so it is harder to find a single global context for the whole post.
So we decided to divide posts into a few parts. And each part of the post usually contains one context. We used the LangChain library to divide posts. After a process of trial and error, we decided to chunk posts - 1000 words per chunk with 100-word overlap with the previous chunk and vectorized only the first three chunks.
We checked whether it was working correctly by searching for the phrase: “flood attack on witness node options to prevent saturation transaction traffic” and expecting to find the related post.
The results were better, but…
The third challenge - embedding calculation was slow… again
When we decided to calculate three embeddings for long posts, the embedding calculation took three times longer.
Thanks to Ollama’s architecture it was relatively easy to solve this problem (though it was expensive - we needed a new graphics card and used another computer for calculating vectors). We added a second server and load balancer to distribute requests to two servers. As a result, the embedding calculation time was reduced to 24 hours.
The fourth challenge - calculating embeddings for newly created post in real time
We found that we had enough time for calculation. The blocks are produced every 3 seconds, but not every block contains posts that require embedding calculations.
The final challenge - what else can influence the results
The PostgreSQL index can have a huge influence on searching results. The pgvector library provides two types of indexes:
- An index with centroids (IVF)
- An index based on neighborhoods (HNSW).
The first index works very quickly, while the second provides better accuracy. However, when we first calculated it, it took more than 25h.
Lessons learned from the first month of the project
- If you want to work with AI, you should learn Python.
- Building an AI project is more about integrating existing LLMs with other systems than writing code from scratch.
- To improve search results and generate high-quality embeddings we had to analyze posts attributes (length, style - including the use of emojis, tags).
- HAF is great. This project confirmed that it is a powerful tool for building highly efficient applications based on Hive data.
- Our team is great too. Thanks to our diverse skill set, we are able to work on a wide range of topics. There is always a specialist available for whatever challenge comes up.
Future
This post described the first month of the project. There were many ups and downs. We learned a lot. There is still much to improve: better deployment (without GPU), improved search relevance and optimization. Some issues were solved, and new ones have appeared.
You can check out the project on GitLab: https://gitlab.syncad.com/hive/hivesense
If you want to try HiveSense, visit https://blog.dev.openhive.network/trending - this is a Denser application (please note it is still not fully production-ready).
try more than batter
Perhaps the way to go is clustering and categorising posts using traditional nlp, before LLM. There also communities to split the data, eg: HIVE Gaming has:
By having clusters and certainty scores for each post for each cluster- its a bit more simple and human readable. Author tags may also help in categorisation.
Hi, I couldn't understand your post. Could you please tell me just a little bit about it so that you don't have to write so much? Can you explain to me easily what your post is about?
This post is a detailed discussion about the software design process for hivesense (well, the first month of that work, since many changes were made thereafter).
To learn what hivesense is (I think this is what you want to know), follow the link in the first paragraph to the introductory post.
Big respect from my side .. because i only see 👀 you are a strongest warrior 💪 in this plartfrom seance many years age to you give suport for every person... because you think like that need to everyone get his power for holding this plartfrom.. again i want to say thanks 😊
Well done 👍
Congratulations @thebeedevs! You have completed the following achievement on the Hive blockchain And have been rewarded with New badge(s)
Your next target is to reach 9000 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCongratulations @thebeedevs! Your post has been a top performer on the Hive blockchain and you have been rewarded with this rare badge
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPYes, I want to thank you again for holding this platform so beautifully and with so much difficulty.
We do hope this great project is sucessful. 🥰