Part 1 is here.

After crafting out the data provider, we can now finally start to build the function to compare and check the schema of a database we are presented with! But, hold on... We still don't have all of the data required to do the task. Since it is about cross-checking and comparing, we will need the data from both sides, the data provider and the database. For now, we seem to not have the ability to get the schema information from the database yet.
In the first part, I mentioned that we can get the columns of a table with PRAGMA table_info("table_name"), and it will return us with a table that contains everything that we need to perform the task. As good as it is, the table returned by it does not use column names that are too friendly for C# code. In C#, we like to have our class attributes in PascalCase, and boolean values are nicer when they start with is, such as isPrimaryKey instead of pk. Luckily, in recent versions of SQLite, we can use PRAGMA functions in select statements, which makes renaming the columns possible with a query like this:
select name as Name, "type" as "Type", "notnull" as IsNotNull, pk as IsPrimaryKey from pragma_table_info("table_name")
Here, the equivalent function for the PRAGMA table_info is pragma_table_info, and we can use this function in a select statement. The rest is just exactly what you can expect from a select statement - choose your columns, give them aliases, and get your result!

SQLite is a very simple database, and it is simple enough to not have booleans... which is why we are getting 1s and 0s here instead of true and false. Good news is, Dapper (which is the what powers SqlKata, the library I am using for SQL queries in the bot) can automatically convert these values into true and false booleans if we are mapping them into boolean types in the code, so it's not an issue here. Anyways, by using this query, we can easily get the data we need for schema comparison. One step forward!
There are several ways to code the logic to compare the columns that we got. First of all, we can use a simple nested for-loop - for each column that we know exists, we find it in the list of columns returned from the database, and we return a false value if a column is not found. It is the most straightforward logic out there, not the most efficient in terms of big O notation, but it doesn't matter because there are only so many columns we have in the database - not significant enough to cause a notable difference. What concerns me more is that it does not look too elegant.. like, it's a nested for-loop. We all don't like nested loops.
The approach that I thought of is to use the C# LINQ function Intersect() and simply find the intersection of the set of columns we are expecting, and the set of columns returned by the database. If the database table contains everything that we are expecting, the number of elements in the result must be the same as the number of columns we are expecting. If the count doesn't match, then we can know the database is missing some columns. Similar to the double for-loop approach, it does not care if the table contains extra tables that we are not expecting (since they do not interfere with the database's usage either way). I also find this as an advantage, as it opens up the chances for future modding plans, since mods can add additional columns to tables without needing to recompile the entire bot due to this database schema validation feature. Well, if we ever get to that point...
Efficiency wise, it is likely less efficient than the double for-loop approach, as the function likely has some overhead to perform the entire operation in O(n) time. A similar case to how hashmaps usually perform worse than simple lists when the amount of data is small, despite using lists might require O(n^2) time to complete the same task. But, the code looks neat! Plus, since the amount of data is small, the difference will not be big either way.
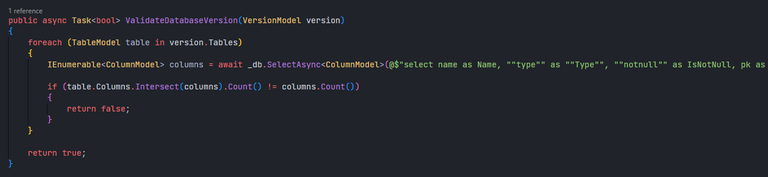
(SQL code truncated by screen width)
So, what do we do after verifying the database schema? There are several cases that might happen...

The database schema is as what we are expecting. In this case, there is nothing the bot needs to do - it should just use the database as is. Nothing fancy, just making sure that we are not using our queries on a database where they will not work.
The database has a known schema, but it is of an older version than what we are expecting. In this case, the database should be upgraded by the bot. So, the bot should run some SQL scripts to add or update the new columns required, and bump the version tag to the upgraded version. If the database is several versions behind, then it should also upgrade it all the way to the latest we can go!
The database has a version tag, but the schema that it is currently holding is not of what we are expecting for that version. In this case, the bot cannot proceed any further, as all we can say is that the database is probably corrupted. We also cannot "fix" it automatically, as it is often a difficult task involving transforming data across different data types, and we risk destroying data. So, for this case, the bot should just throw an error and exit from execution.
The database lacks the version tag needed to identify its version and hence prevents us from cross-checking its schema with what we are expecting. In this case, the database can either be blank or not, but to simplify things, we can just assume that we can start adding the necessary columns into it, and we will be able to start using it. Not the most sophisticated approach (and we risk writing into a database that we should not be writing into), but it is simple, and at the same time providing us with the freedom to supply a custom database if needed for modding. Well, again, if we get to that point...
These are pretty much all of the cases that might happen after we verify the database schema. Now, to turn them into code...
I added a method in the DatabaseMigrator class called MigrateLatest(), which will be the method that will be called by the bot's entry function to check the database and upgrade it if necessary. In the method, it first gets the version tag stored in the database and the latest schema that it is going to use. If it doesn't get a version tag, it assumes that it should start creating the tables it is going to use in the database, and hence will do that and finish its function there. Otherwise, it will also get the expected schema information for the version from the data provider. If the data provider doesn't return anything for that version, it means that the version is not a known version, and hence we are not able to continue with it (it in some ways fall under case 3 above). Otherwise, it will check if the database is having an expected schema for the version tag it is holding, and throw an error if the database looks corrupted. If everything looks well, it will finally check if an upgrade is needed for the database, and do it if it is required.
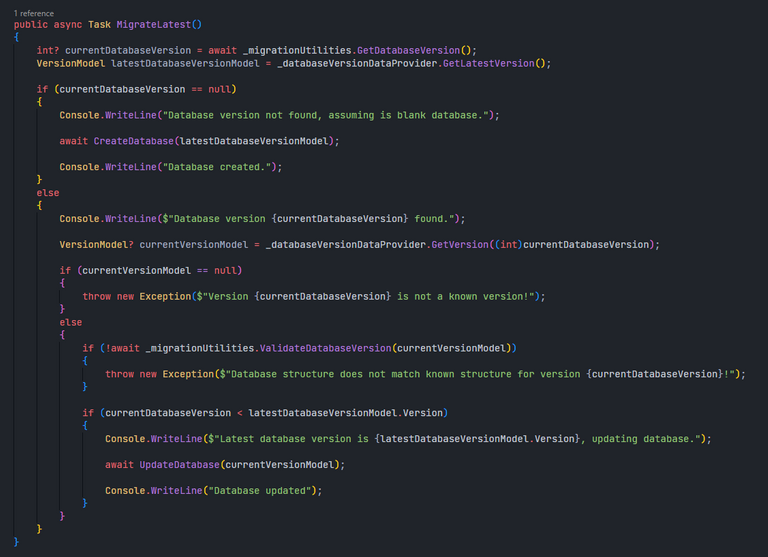
MigrateLatest() method.What about the code for the CreateDatabase() and the UpdateDatabase() methods? They are actually surprisingly simple... since the data provider returns a version's creation script in its version model object, the CreateDatabase() method simply executes it from the version model that is passed to it as a required argument. For the UpdateDatabase() method, since we have a GetUpdateScripts() method available from the data provider, we will just use it to get all the scripts that are required to move the current version to the latest version, and execute the scripts in order.

CreateDatabase() method.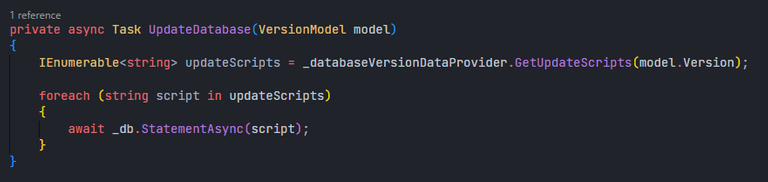
UpdateDatabase() method.It doesn't look that hard, eh? Now all we need to do is call MigrateLatest() in the bot's entry function and we can be sure that if everything goes without problems, the bot will be enjoying its latest database. Otherwise, the bot will simply not run at all.

MigrateLatest() in the bot's entry function.That's all about it!

Comparing this with the EF Core's migrations, this approach uses a "version" instead of a history of migrations done on a database (which is, as far as I know, the way EF Core takes notes on what migrations had been applied). I personally find it that keeping a history of what had been done is not really important in our use case, as all we care is if the database is in a form that is ready for us to use. If the version looks good, and the schema looks good, it's going to be fine. The database can be manually created, edited, patched for it to "look fine", but it doesn't matter - the bot can use it? It's fine. It feels more flexible, and at the end of the day, it does what we need it to do.
I will perhaps try to store the database schema information in JSON files and let the data provider read from them in the future, so I will not have a data provider source code file that goes over 10k lines. A 10k line file sounds like hell to maintain... even if it's only me who is going to look at it, it still feels awful! Well, off into the to-do list it goes. If we ever get to that point...
I think that's all for now! See you next time :)

Thank you for sharing this post on HIVE!
Your content got selected by our fellow curator elizacheng & you received a little thank you upvote from our non-profit curation initiative. Your post will be featured in one of our recurring curation compilations which is aiming to offer you a stage to widen your audience within the DIY scene of Hive.
Next time make sure to post / cross-post your creation within the DIYHub community on HIVE and you will receive a higher upvote!
Stay creative & hive on!
Dear @lilacse, sorry to jump in a bit off-topic.
May I ask you to review and support the new proposal (https://peakd.com/me/proposals/240) so I can continue to improve and maintain this service?
You can support the new proposal (#240) on Peakd, Ecency,
Thank you!