This post is the adaptation in French of this one, that I released a couple of months ago, and that focuses on the hunt for new phenomena at CERN’s Large Hadron Collider. As can be seen from the posting date, it was long overdue…
Je pense que c’est la première fois que je mets si longtemps pour m’occuper de la version française d’un post. Mais tout vient à point pour qui sait attendre, n’est-ce pas ? Dans ce blog, je vais m’atteler à poser une question, et à tenter d’y répondre : comment recherche-t-on des phénomènes nouveaux au Grand Collisionneur de Hadrons du CERN, le LHC ?
Ce post a pour vocation d’expliquer en détails le lien entre une analyse de physique au LHC et la tonne de données qui y est enregistrée. On parlera donc de détecteurs, de prédictions et de données. Comme d’habitude, la version “1 minute” de cette histoire… se trouve à la fin du post.

[Crédits: Image originale par Daniel Dominguez (CERN) ]
1 petabyte de données par seconde !
Le LHC fut conçu pour produire plus de 600,000,000 collisions par seconde dans les détecteurs ATLAS et CMS. 600 millions ! Ce nombre en soi est juste énorme, et pose problème au système d’acquisition de données des détecteurs. En effet, ce taux de données est supérieur par plusieurs ordres de grandeur à ce que l’électronique peut faire aujourd’hui.
On parle d’un rythme de production de données d’1 petabyte par seconde, ce qui est équivalent au contenu d’environ 200,000 DVDs par seconde. Bien évidemment, c’est beaucoup trop pour être enregistré… D’ailleurs, qui me traduit cela en nombre de disquettes (je vous parle d’un temps que les plus jeunes d’entre nous ne peuvent pas connaître…) ?
Mais cette situation n’est pas trop grave, car nous n’avons pas besoin d’enregistrer toutes ces données, et nous pouvons nous payer le luxe de nous concentrer uniquement sur des collisions intéressantes du point de vue de la physique. Cela nous réduit le taux de données à 200 mégas par seconde, ce qui est gérable électroniquement parlant.
La réduction du taux de données est effectuée à l’aide d’une procédure très rapide et automatique, que l’on appelle en anglais un système de trigger. Je ne traduirai d’ailleurs pas cela, car la version française sonne trop bizarre à mon oreille…

[Crédits: Manfred Jeitler (CERN) ]
Et ces triggers, donc ?
De façon plus pratique, cette procédure de trigger scanne chaque collision afin d’y trouver une quantité importante d’énergie déposée dans le détecteur ou des traces du passage de particules très énergétiques. Un événement (ou collision) qui contient cela est par nature intéressant et suffisamment rare pour être étudié de près. Cela permet de réduire le taux d’événements à environ 100,000 par seconde. C’est toujours trop pour l’acquisition des données, mais c’est mieux.
Ensuite, un processus de ‘reconstruction’ permet de relier traces et dépôts énergétiques à des particules bien précises, comme par exemple des électrons, des muons, etc. On pourra donc avoir une idée de ce qu’il s’est passé durant la collision. Avons-nous affaire à un processus ennuyeux et usuel, ou à quelque chose de plus croustillant ?
En moins de 0.1 seconde, on peut répondre à cette question et décider d’enregistrer l’événement sur disque ou non. On arrive ainsi à un taux (voulu) d’événements enregistrés sur disque d’environ 100 par seconde. Cela nous donne 15,000 terabytes de données par an par détecteur. Pas mal non ? Il nous reste à les décortiquer pour mieux comprendre le fonctionnement de l’univers !

[Crédits: Florian Hirzinger (CC BY-SA 3.0) ]
Signal et bruit de fond ?
Donc nous avons 15,000 TB de données par an sur disque. Il nous faut alors trouver des choses intéressantes là-dedans, et bien entendu comparer avec les prédictions pour vérifier que tout est sous contrôle. Ces prédictions peuvent être effectuées dans le cadre du Modèle Standard (on teste la théorie) ou au-delà (on regarde ce qui est viable pour une extension du Modèle Standard).
À partir d’ici, on va sélectionner un certain nombre de collisions enregistrées en fonction de leurs propriétés. Par exemple, supposons que l’on choisisse un signal qui prédit deux muons dans l’état final, de l’énergie manquante (matière noire ou neutrinos) et deux jets de particules fortement interagissantes (voir ici pour une définition). Ensuite, on impose que ces différents objets soient bien séparés les uns des autres dans le détecteur. Cette sélection nous permet de réduire le nombre impressionnant de collisions enregistrées à quelques centaines ou milliers.
[Crédits: CERN]
Ainsi, on va sélectionner une grosse partie du signal traqué. Mais la vie n’est pas si simple… Notre sélection va également sélectionner des événements de bruit de fond (des processus différents de celui recherché, mais donnant lieu au même état final).
À la recherche d’une aiguille dans un botte d’aiguilles
Généralement, tout signal est noyé dans le bruit de fond correspondant (même état final, mais venant d’un processus différent de celui recherché ; je me répète, je sais). Si parfois on parle de la recherche d’une aiguille dans une botte de foin, en fait ici il s’agit plutôt de la recherche d’une aiguille dans un botte d’aiguilles.
On va donc ajouter des critères supplémentaires sur les événements sélectionnés, comme par exemple sur la façon dont les objets détectés doivent être orientés les uns par rapport aux autres, ou leur énergie, et ainsi de suite. Le but est toujours le même : sélectionner autant d’événements de signal que possible et rejeter autant d’événements de bruit de fond que possible.
Prenons un exemple, dans la figure ci-dessous, qui concerne la recherche de matière noire par la collaboration CMS du LHC.
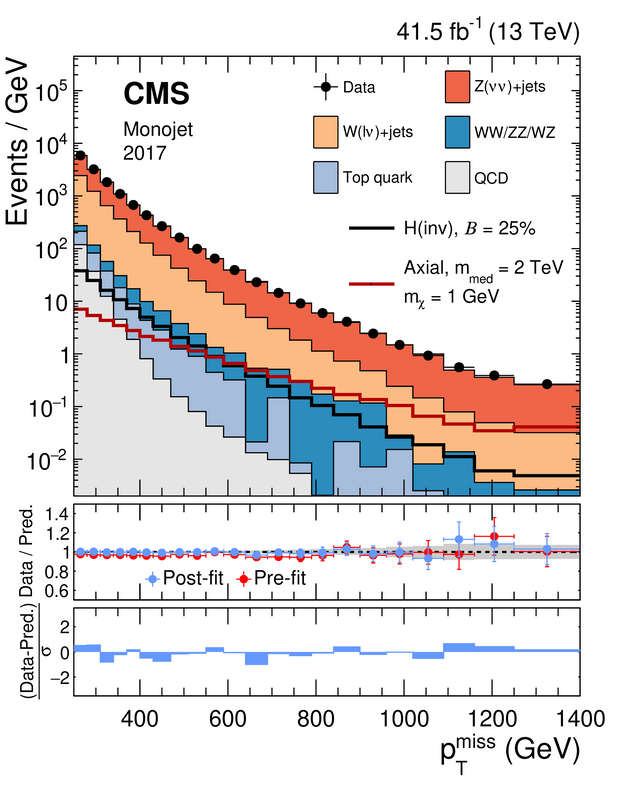
[Crédits: JHEP 11 (2021) 153 (CC BY-4.0)]
La sélection concerne les événements qui ont été enregistrés durant le run 2 du LHC. Le signal recherché correspond à de la production de matière noire avec un jet de particules fortement interagissantes très énergétiques. Comme la matière noire est peu interagissante (voir aussi ici), elle traverse le détecteur sans y laisser aucune trace une fois produite.
Le bilan énergétique des événements sélectionnés doit donc faire apparaître de l’énergie manquante (emportée insidieusement par la matière noire), en prenant en compte le fait que l’énergie est conservée. Notre signal contient donc un jet, et de l’énergie manquante.
C’est ce qui est reporté sur la figure : le taux d'événements en fonction de leur quantité d’énergie manquante. À gauche de la figure, les événements ont peu d’énergie manquante. À droite de la figure, ils en ont beaucoup plus. Chaque couleur correspond alors aux attentes (prédictions) pour un processus donné du Modèle Standard, auxquelles ont peut superposer ce qui est observé dans les données (les points noirs avec leurs barres d’erreur).
Un observe un bel accord entre données et Modèle Standard. Cela nous permet d’extraire des contraintes sur les modèles de matière noire. Le signal associé doit être suffisamment faible pour ne pas perturber cet accord “données et Modèle Standard”.

[Crédits: La collaboration ATLAS (CERN)]
Et notre analyse LHC préférée ?
Il est temps de résumer ce blog, qui en devient presque trop long. Le LHC nous livre des centaines de millions de collisions par seconde, ce qui est bien trop pour tout système électronique. Chaque détecteur est donc équipé d’un système de déclenchement (trigger, que j’ai traduit pour une fois) permettant d’étiqueter ou non une collision comme intéressante.
Si c’est le cas, elle sera alors enregistrée sur disque (on parle de 100 collisions enregistrées par seconde). Le choix de l’enregistrement ou non est dicté par la quantité d’objets très énergétiques observés dans le détecteur.
À partir de là, on peut effectuer une analyse de physique et rechercher un signal donné dans les données. Ce signal peut être du Modèle Standard (on veut étudier une particule précisément), ou au-delà (on recherche alors un phénomène nouveau).
Celte analyse va mettre en place des critères de sélection sur les événements enregistrés, dont le but est de sélectionner autant d’événements ayant potentiellement notre signal pour origine que possible, et aussi peu d’événements pouvant venir du bruit de fond que possible,
Ensuite, il faut vérifier ce que nous avons dans les données après la sélection. Sommes-nous compatibles avec le bruit de fond ? Y a-t-il de la place pour un excès ou une anomalie, et donc pour un signe d’une nouvelle physique ? Que de questions…. et pas mal de boulot vu qu’on va essayer plein de possibilités pour comprendre comment notre univers pourrait fonctionner.
Sur ce, je vous souhaite une bonne fin de soirée, et n’hésitez pas à me poser vos questions !
The last thing I knew about the particle accelerator was that it was suspended, I think it was in Switzerland, right? I also know that it is a way to recreate small big bangs, my question is, have replicas of the big bang been created in laboratories? another question can these machines also produce black holes?
Thanks a lot for these questions!
The Large Hadron Collider is indeed the accelerator localised at the French-Swiss border. Its third operation run started last July, so a couple of months ago. The reason of the previous shutdown (of a couple of years) was for upgrades in the machine and the detectors.
In its mode where heavy nuclei are collided, the machine allows us to study the universe as it was a few moments after the Big Bang, and it thus allows us to understand this early history of our universe better. We do not recreate big bangs, but what is happening is more like a picture reproducing conditions that are close to those from the early moments of the universe.
If you take certain theories as granted then yes. However, these theories also predict that those produced black holes quickly evaporate (in a few nanoseconds). For now, no black hole has been found in data.
I hope this answers your question. Do not hesitate to come back to me if needed.
Cheers!
Super article !
J'aime beaucoup l'image de la botte d'aiguilles, en effet trouver une aiguille dans une botte de foin avec un peu d'organisation (et des ordis xD) c'est possible.
On a juste à tirer chaque brin de paille jusqu'à trouve l'aiguille.
En revanche dans une botte d'aiguille, il faut avoir une idée précise de ce que l'on cherche, mais c'est tout de suite moins évident !
En filant la métaphore, filtrer un signal reviendrait à sélectionner une poignée d'aiguilles dans la botte tout en cherchant à s'assurer que l'intégralité du signal de trouve dans la poignée.
Ça résume bien la situation je trouve ^^
Ton resume est tres precis, et c'est exactement ce que l'on essaie de faire. je ne l'avais jamais presente de cette facon, et je le ferai a l'avenir !
Note qu'ici, la tache la plus complexe etant bien entendu la conceptualisation de la methode pour selectionner la bonne poignee d'aiguilles. Y aller au pif ne donne generalement pas de bons resultats !
A bientot !
Content que mon imagination serve à quelque chose 😆!
C'est sûr que c'est plus facile à dire qu'à faire en effet! Mais si c'était simple on aurait pas des labos entiers remplis de gens passant leurs journées à essayer de trouver une réponse, c'est aussi pour ça que c'est passionnant la recherche 🙂
Exactement ! Je dirais meme plus : passionnant... et amusant !
meme si ce que tu ecris a l'air simple, en fait pour poser une question il faudrait deja comprendre un minimum, bon bah la sans les bases evidement ca se complique 🤣
Hehe. Tu peux toujours regarder dans les posts plus anciens si ca te tente :)
Thanks for your contribution to the STEMsocial community. Feel free to join us on discord to get to know the rest of us!
Please consider delegating to the @stemsocial account (85% of the curation rewards are returned).
You may also include @stemsocial as a beneficiary of the rewards of this post to get a stronger support.
✒️ Pour cette explicitation "initiation" sur la question "comment recherche-t-on des phénomènes nouveaux au Grand Collisionneur de Hadrons du CERN, le LHC ?", nous vous offrons 💝100 points-fr💝
🎁 Recevez en plus un bonus de 5 points-fr pour votre sélection et ce pourboire : !LUV
💰 Plus de Tokens de 2eme couches vous attendent dans les posts de sélections et de récompenses
Récompense Multi-engagements des Francophones
@bonus-fr(1/10) gave you LUV. tools | wallet | discord | community | <>< daily
tools | wallet | discord | community | <>< daily
HiveBuzz.me NFT for Peace
Merci. Bonne jornee a vous !
Dear, @lemouth
May we ask you to review and support our @cryptobrewmaster GameFi proposal on DHF? It can be found here
If you havent tried playing CryptoBrewMaster you can give it a shot. Our @hivefest presentation available here on the YouTube with a pitchdeck of what we building in general
Vote with Peakd.com, Ecency.com, Hivesigner
Thank you!