I've recently been introduced to DataCamp, which does the job. But then I stumbled upon Kaggle again and decided to join to see what is happening there. It turns out it's free, and it has datasets to play with, and it has competitions to determine whose mettle is made from metal.
A few days after joining, they launched a Whale Identification competition. I decided to jump into it and see how much Machine Learning I still remember. About time to update those skills too!
First Submission: What's a CNN again and is it as fake as the news network?

Kaggle has many great features. The fact that you can run most of your code in Jupyter notebooks is great, and the fact that there are good Samaritans who give their kernels away so noobs like me have a place to start, plus you can enter straight from your notebook once you figure out where to look... basically, it's all great and they're not even paying me to say this! This is handy because the datasets are often large downloads, and we're experiencing blackouts here in shithole country again.
One such kernel contained a Convolutional Neural Network (CNN). From my Udemy course, I vaguely remember that it is indeed convoluted, though the Udemy explanations were more clear than the Wiki ones. Regardless, I'm using this post mostly as an attempt at a solution document for my first Kaggle competition, so I won't go into too much detail regarding explanations of which I'm not too sure about myself at the moment.
I branched the starter code and got it up and running, yielding the following result:
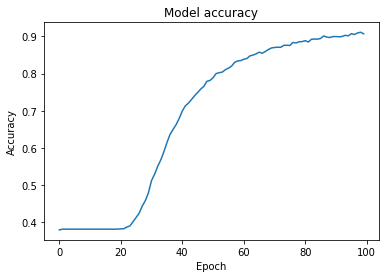
Here I am on the leaderboard. Cthulu be praised!

Second Submission: Oh, now I remember
Already nearly 90% accuracy and they are not satisfied?! Well, I could immediately see a few tweaks which would improve matters. After finding my way around the notebook, I managed to make my very first submission to a Kaggle competition and that even rhymes. Even my mom was proud. Of the competition submission, not the rhyming.
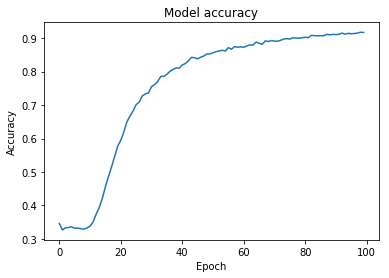
What I did here was I replaced the ReLu activation function with ELU. Thank you, good old Wikipedia! But then I noticed that there is quite a large dropout rate. It's huge. The recommended dropout rate is usually between 0.2 and 0.5, so that gave me another idea for a tweak.
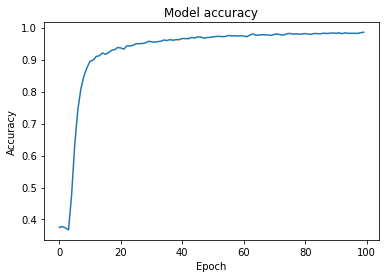
That's with a thumb-suck dropout rate of 0.35. It does a whole lot of epoch training with very small yet steady increments in accuracy and a definite slow and steady lowering of the loss function too. I was rather pleased and I even ended up in the top 100 on the leaderboard! Not too shabby for my very first Kaggle competition, I'd say.
Third Submission: Let's try something different
I figured I could just tweak the dropout rate some more, but upon reading up on dropout rates and CNNs, I stumbled upon the idea of batch normalisation. Well, OK let's do that then.
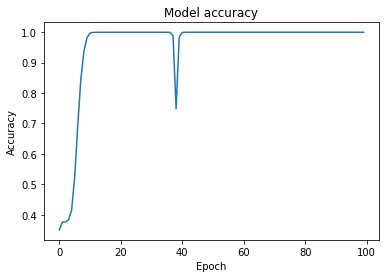
This increased my standing on the leaderboard quite a bit, but something is clearly wrong there. Nevertheless, I have a few more tricks up my sleeve to try. I'm quite excited by this new playground I've discovered!

Congratulations @gargunzola! You received a personal award!
Click here to view your Board of Honor
Do not miss the last post from @steemitboard: