RSS Delivery
No one likes polling.
Ever since the dawn of the open RSS ecosystem, applications poll RSS feeds. That's how it works, right? They check a feed for updates on some kind of schedule. Maybe, if they feel like tackling an unsolvable problem out of sheer curiosity, they add some learning algorithm to figure out when the feed actually changes to save resources.
Polling, most of which is done in regular intervals, is the most reliable method of knowing when a feed is updated within a decentralized ecosystem no one controls. Even today this is how most RSS feed aggregation runs because it's the only way to avoid missing anything. This isn't a problem in its own right, but it's inefficient.
It becomes an issue when:
- A feed gets extremely popular, which can easily cause unwanted bandwidth costs or even take down smaller operations.
- A single host manages a significant amount of RSS feeds. They add up!
- Time-sensitive content is released. Say one wants to publish a breaking news story or a live steam. Polling will catch it late, and increased polling frequencies are frowned upon (often rate-limited) due to the above issues.
Until now, users and services have often relied on other options for updates, particularly for time-sensitive content:
- Outside systems like social media have always offered a means to notify users of updates, but it's not a great user experience for anyone. This helps #3, but still requires polling. Often it causes more polling with the user refreshing rapidly.
- Centralized systems, usually implemented by podcast services as back-ends for client applications -- especially on mobile -- offer a way to hide polling from users. It helps #1 & #2, and works, but it's still polling and hiding this from users can cause confusion.
- Otherwise entirely closed systems with their own notifications (YouTube, Twitch ... the list goes on). These usually solve the issues for users, but it's no longer open! I'm not going to discuss the philosophical implications of closed systems, but they still get real time updates wrong, because real time updates are hard.
What about WebSub?
Yes, WebSub helps with some of the above issues. It has two main problems:
- WebSub attempts to move the problem from polling feeds to maintaining WebSub subscriptions. It's great in theory. In practice it's just another problem to solve and it's ultimately just another unreliable link in the chain. Applications frequently fall back to polling.
- WebSub requires a server to obtain updates. This isn't an issue for podcast applications that run their own services, but what about standalone applications as intended by the spirit of open RSS? What about the last mile? Standalone applications still end up polling, and especially get left out of time-sensitive content.
The Last Mile
The last mile is a relatively new problem within the scope of the open RSS ecosystem. Every application used to poll for content. Live streams, outside of obscure internet radio, didn't even exist or weren't widespread enough to be relevant.
Fast forward to today, most podcast applications run their own services and/or depend on large aggregators to do the heavy lifting. Many trusted Apple for this task, until they couldn't, and the Podcast Index only stepped up as an alternative because it's still such a difficult problem. Even more, the aggregators still have to be polled! They don't have the resources to become a notification system en masse.
Podping.cloud
Enter Podping.cloud:
Podping is a blockchain based global notification system for podcasting. Feed urls are written by the publisher to the blockchain within seconds of a new episode being published. Anyone can monitor for those updates and only pull a copy of that feed when it shows up on the chain.
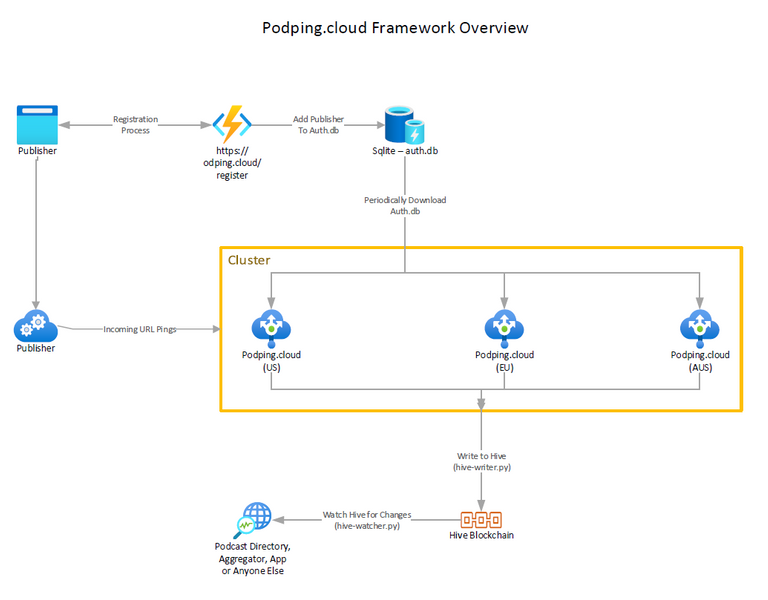
What does that mean? It consists of two parts:
- An on-boarding mechanism for hosts to migrate to with ease -- something similar to WebSub but simpler to manage.
- A standardization of data interchange mechanisms -- the "podping" namespace -- to broadcast podcast updates onto the Hive* blockchain.
*Note: This is really just a specification of a JSON schema. Hive is an implementation detail.
Decentralized podcast updates!
Given Podping, a standardized way to communicate podcast updates into Hive, anyone can listen for them on the Hive blockchain. An important characteristic of what the Hive community has developed is a standardized HTTP API for applications to utilize, as opposed to having to download and manage the Hive blockchain themselves (though they could if they wanted to).
What does this look like for an application? Below are a few real transactions from the Hive blockchain:
{"_id": "cabd5cc591662b4cb131fb546ae9189d104a00ee",
"block_num": 54014222,
"id": "podping",
"json": "{\"version\":\"0.2\",\"num_urls\":3,\"reason\":\"feed_update\",\"urls\":[\"https://feeds.buzzsprout.com/981862.rss\",\"https://feeds.buzzsprout.com/1722601.rss\",\"https://feeds.buzzsprout.com/1287197.rss\"]}",
"required_auths": [],
"required_posting_auths": ["hivehydra"],
"timestamp": "2021-05-19T02:39:06Z",
"trx_id": "ebd5b45772e119c38f75e246d4b70d60ee527716",
"trx_num": 23,
"type": "custom_json"}
{"_id": "6b7fe74973283bf99d76ef9b81ced193c43ebe84",
"block_num": 54014229,
"id": "podping",
"json": "{\"version\":\"0.2\",\"num_urls\":2,\"reason\":\"feed_update\",\"urls\":[\"https://media.rss.com/njb/feed.xml\",\"https://feeds.buzzsprout.com/1749995.rss\"]}",
"required_auths": [],
"required_posting_auths": ["hivehydra"],
"timestamp": "2021-05-19T02:39:27Z",
"trx_id": "394ecb5449f6a7d9472432915ed2241628e0716e",
"trx_num": 20,
"type": "custom_json"}
{"_id": "c6ed805969a3c86634f34352e44a232e907336e1",
"block_num": 54014236,
"id": "podping",
"json": "{\"version\":\"0.2\",\"num_urls\":1,\"reason\":\"feed_update\",\"urls\":[\"https://feeds.buzzsprout.com/1575751.rss\"]}",
"required_auths": [],
"required_posting_auths": ["hivehydra"],
"timestamp": "2021-05-19T02:39:48Z",
"trx_id": "b3a97ec7bf97604194755913953b28b6de21c403",
"trx_num": 12,
"type": "custom_json"}
{"_id": "73c63d127e040049f0d6c2f118c1c00e46da17da",
"allow_curation_rewards": True,
"allow_votes": True,
"author": "<redacted>",
"block_num": 54015435,
"extensions": [{"type": "comment_payout_beneficiaries",
"value": {"beneficiaries": [{"account": "hiveonboard",
"weight": 100},
{"account": "tipu",
"weight": 100}]}}],
"max_accepted_payout": {"amount": "1000000000",
"nai": "@@000000013",
"precision": 3},
"percent_hbd": 10000,
"permlink": "<redacted>",
"timestamp": "2021-05-19T03:39:54Z",
"trx_id": "7d4012b4b7e4901bbaf910a71166a78f5ac9b186",
"trx_num": 22,
"type": "comment_options"}
{"_id": "502ddccc9a1e4bb86b7379497e6b17e943c869d4",
"block_num": 54014474,
"id": "sm_find_match",
"json": "{\"match_type\":\"Ranked\",\"app\":\"steemmonsters/0.7.89\"}",
"required_auths": [],
"required_posting_auths": ["nandito"],
"timestamp": "2021-05-19T02:51:45Z",
"trx_id": "b41cf36a88d798d15e31b1d2b718cd7fa4176b1b",
"trx_num": 49,
"type": "custom_json"}
{"_id": "1dc0e544c25978fcf868e40623e930d5bbdc97fa",
"block_num": 54014474,
"id": "sm_submit_team",
"json": "{\"trx_id\":\"8a965173a51cf0457264196066febf3040d9c720\",\"team_hash\":\"946c2011bd2ec8844fcdc2bbf946a738\",\"summoner\":\"C1-49-SM0LILHETC\",\"monsters\":[\"C1-64-TPHW58AV34\",\"C1-50-1AMDZHJ7OG\",\"C1-47-S6HDP0EA5S\",\"C1-62-AQOTC401J4\",\"C1-46-1BP1BKEY3K\"],\"secret\":\"TZte3wNaM7\",\"app\":\"steemmonsters/0.7.24\"}",
"required_auths": [],
"required_posting_auths": ["postme"],
"timestamp": "2021-05-19T02:51:45Z",
"trx_id": "8ff17c754ff1d9621e9e0014439e720086ab5e85",
"trx_num": 50,
"type": "custom_json"}
A few interesting things to note here. It's nice to have all of the information, but it's a bit of a fire hose. How can we clean this up? We can hide it within our application, which might be acceptable for some servers... however it's still all unnecessary bandwidth. Particularly the last two non-Podping operations as well as the non-custom_json type.
Walking the last mile
In order for this to be efficient for client applications -- especially mobile applications with limited resources -- there's a couple things we need to address. Note: I am only familiar with the beem python library at this moment in time, so it's possible these two points are moot.
- Server side filtering of
custom_jsonoperations. Currently the python implementation,beemdoes this on the client side, hiding it from the user. It still pulls in every block even if you tell it to only look for thecustom_jsonoperation. - Server side filtering of the
custom_jsonid-- even if we pulled in onlycustom_jsonoperations, we're still getting other data from other applications. Really, we only care aboutid='podping'.
Given those two changes, we can size down the fire hose to the following podping operations:
{"_id": "cabd5cc591662b4cb131fb546ae9189d104a00ee",
"block_num": 54014222,
"id": "podping",
"json": "{\"version\":\"0.2\",\"num_urls\":3,\"reason\":\"feed_update\",\"urls\":[\"https://feeds.buzzsprout.com/981862.rss\",\"https://feeds.buzzsprout.com/1722601.rss\",\"https://feeds.buzzsprout.com/1287197.rss\"]}",
"required_auths": [],
"required_posting_auths": ["hivehydra"],
"timestamp": "2021-05-19T02:39:06Z",
"trx_id": "ebd5b45772e119c38f75e246d4b70d60ee527716",
"trx_num": 23,
"type": "custom_json"}
{"_id": "6b7fe74973283bf99d76ef9b81ced193c43ebe84",
"block_num": 54014229,
"id": "podping",
"json": "{\"version\":\"0.2\",\"num_urls\":2,\"reason\":\"feed_update\",\"urls\":[\"https://media.rss.com/njb/feed.xml\",\"https://feeds.buzzsprout.com/1749995.rss\"]}",
"required_auths": [],
"required_posting_auths": ["hivehydra"],
"timestamp": "2021-05-19T02:39:27Z",
"trx_id": "394ecb5449f6a7d9472432915ed2241628e0716e",
"trx_num": 20,
"type": "custom_json"}
{"_id": "c6ed805969a3c86634f34352e44a232e907336e1",
"block_num": 54014236,
"id": "podping",
"json": "{\"version\":\"0.2\",\"num_urls\":1,\"reason\":\"feed_update\",\"urls\":[\"https://feeds.buzzsprout.com/1575751.rss\"]}",
"required_auths": [],
"required_posting_auths": ["hivehydra"],
"timestamp": "2021-05-19T02:39:48Z",
"trx_id": "b3a97ec7bf97604194755913953b28b6de21c403",
"trx_num": 12,
"type": "custom_json"}
This on it's own is a huge improvement, but we can do more...
One step further
See the json attribute? That's our Podping schema! What if we only subscribe to one or two podcasts? We don't need the rest of the results.
Thankfully, there's a straightforward way to handle this: JMESPath
JMESPath is a query language for JSON.
Let's say we only want to get results from the podcast "Quality during Design" in the above list. We can test this in a quick way with the jp cli tool and the JMESPath contains function.
echo '{"version":"0.2","num_urls":3,"reason":"feed_update","urls":["https://feeds.buzzsprout.com/981862.rss","https://feeds.buzzsprout.com/1722601.rss","https://feeds.buzzsprout.com/1287197.rss"]}' \
| jp "contains(urls, 'https://feeds.buzzsprout.com/1722601.rss')"
true
Behold! We just defined a mechanism to query Podping json from a custom_json operation. In this example, the contains function being run by jp is returning true, telling us that this example indeed includes the feed URL we care about.
Why is this important? Couldn't we just parse the json object in our code and check for the URL?
Well, yes... but JMESPath provides us a way to run this query on the API server, without the API server requiring knowledge of our dataset. Meaning, given an implementation of this query on the Hive API, we would happily only get the results we need from the API.
If we only subscribed to one podcast we could get update notifications for it without having to parse through all new Hive blockchain events.
This is truly potential for a whole new generation of a decentralized notification system, and Podcasting 2.0 is driving it.
Hopefully some of the above ideas can be incorporated into the Hive ecosystem in a way that will benefit everyone.
Reposted from https://write.agates.io/podcasting-2-0-the-last-mile
I made Hive Plug & Play to solve the
custom_jsonop filtering and search problem for Hive. With it you can search and subscribe tocustom_jsonops from a particularidsuch aspodping. You can either use the public node I have made freely available (https://plug-play.imwatsi.com/) or run your own node and customize it (https://github.com/imwatsi/hive-plug-play).Well, this sounds very interesting because I guess apps can poll the blockchain for whatever data points they want and not get all the rest, so it makes it that much more easy and straightforward for them.
Hello, This is @macchiata from the @OCD team. We saw that you already posted your first post here in Hive. That's an interesting post. It would be awesome if you do an introduction post that way could meet other hivers who are also into this . You can refer to this intro post for reference:
My Introduction to the Hive Community
There's no specific format on how you do your intro post, but there are some suggested content that we would love to see in your post. Information like who are you and where you're from, how did you discover Hive or who invited you, what types of content you want to see here and the types that you want produce, and what are your expectations in this platform.
There's no pressure on this. You can choose on whatever information you would like to share.
If you have questions, you can hop into OCD's Discord server and we'll gladly answer your questions. For now, @lovesniper will follow you and we are looking forward to your intro post!
I will nudge @alecksgates about posting an intro!
Awesome, I look forward reading that.
Your content has been voted as a part of Encouragement program. Keep up the good work!
Use Ecency daily to boost your growth on platform!
Support Ecency
Vote for Proposal
Delegate HP and earn more
Congratulations @alecksgates! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
Your next target is to reach 100 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
Support the HiveBuzz project. Vote for our proposal!