Hi Steemians! This post is an add-on to my previous post "Do you have to be a "genius" to work on machine learning?". If you have no idea of what machine learning is, take 3 minutes during your lunch hours or teatime to read my last post. You'll then realize that machine learning is not that hard to understand!
This time, let's see how easy it is to start your own project! I'm not gonna talk about hardcore programming stuff so don't worry.
Step Number One: Getting the data!
Even if you are a maths genius and have invented a state-of-the-art machine learning model, it's completely useless if you don't have any data at hand! Many beginners will easily give up picking up machine learning simply because they don't get the data to play around. Fortunately, AI community always keeps on sharing benchmark data sets online for free. There are a variety of them for you to play with different kinds of models. Let's walk through some of them!
MNIST --- Image classification
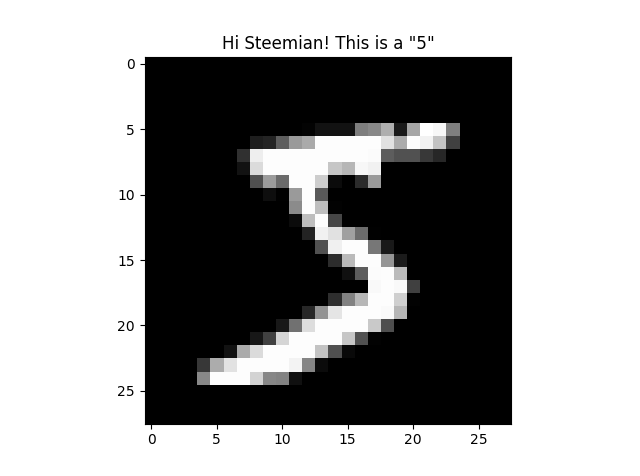
The MNIST data set is among the most popular data sets used for illustration and testing models. MNIST stands for "Modified National Institute of Standards and Technology". The data set contains a large number of handwritten digits, each of which is a 28 x 28 image. There are altogether 60,000 images for training the model and 10,000 images for testing! I have visualized the first image of the data set using matplotlib in Python as follow:
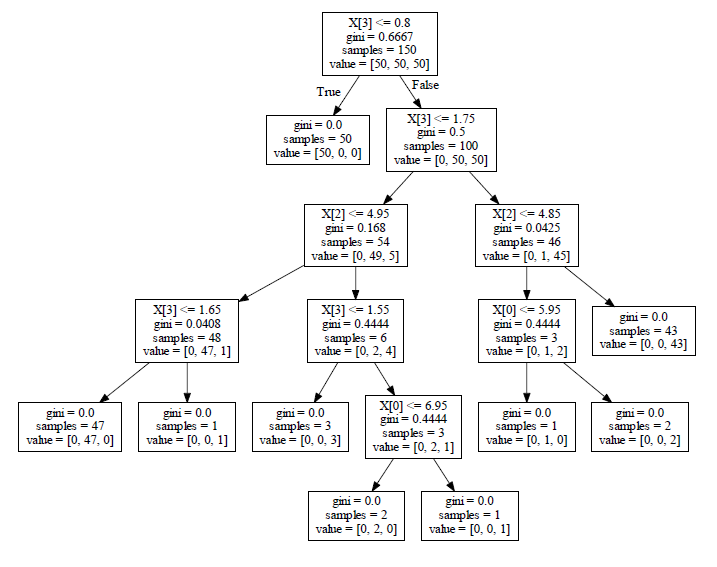
Iris --- Simple data set for building the first decision tree!
I think every machine learning practitioner must have used (or at least have heard of) the Iris data set, which is sometimes implicitly contained in some machine learning libraries already for testing purposes. If you want to do practice on classification modelling, Iris data set is a good starting point. You are given the sepal's length and width, as well as the petal's length and width for each data point. You are supposed to classify each of them to one of the 3 iris species correctly. Using the Python module scikit-learn and pydotplus, I've created the following decision tree from the Iris data set:
Open-source resources are everywhere!
If you're looking for more free data sets for practice, here are 2 recommendations:
- UC Irvine Machine Learning Repository: A lot of commonly used benchmark data sets are available in this repository, including the Iris data set that we just had a look.
- Kaggle: I highly encourage every machine learning lover to visit Kaggle. Not only are there lots of free data sets, there are also plenty of predictive challenges with cash prizes! I'm not a top Kaggler and what I want to say is that you don't always need to be the No. 1 in competitions. Learning how others build the models from scratch with cool ideas is often the best way to improve your techniques. The data types are diversified and most of the competitions are very interesting!
Don't rush. Understand your data first.
You don't need to rush feeding the data directly to a model once you've got the data. It's always good to do some exploratory analysis. Visualizing the data can help you realize some patterns in your data which can be useful in the next step when you are writing up the model. There are lots of libraries for doing visualization. For Python, I love matplotlib and seaborn (which builds on matplotlib). If you are used to writing scripts in R, ggplot2 will be a good choice.
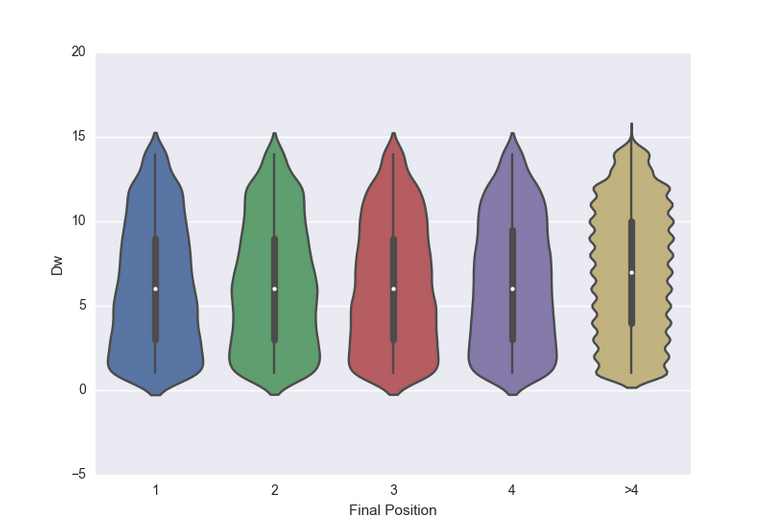
An interesting violin plot created from seaborn for one of my personal projects
Golden rule: don't stick to one model!
What models are available?
It's a good way to learn if you try to write the machine learning algorithms by yourself from scratch to strengthen your understanding in theories! But in real applications, using open-source libraries is often a better choice since most of them are the products after years of hard work by a team of experts.
I haven't used R for a long time, so I can't give a lot of suggestions of which library to use. I used to apply the library h2o, which supports various algorithms like random forest, gradient boosting decision tree, multi-layer perceptron and unsupervised methods like clustering and principal component analysis. (It's okay if you're not familiar with these jargons. Reading the books I suggested in the previous post can help. Of course, Wikipedia is always your best friend).
For Python, you must need to know scikit-learn, which is a comprehensive library containing dozens of classical models. If speed does matter, there are also other algorithms which are very efficient. For structured data, a good choice is xgboost created by Dr Tianqi Chen, which is an enhanced version of classical gradient boosting model. If you're playing around with images or texts, then I would recommend Keras, which builds on Theano and Tensorflow to construct deep learning models very efficiently using the GPU (graphics card) of your computer, provided that your computer has a reasonably good graphics card.
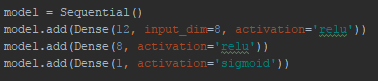
Using Keras you can build a neural network very easily by adding layers sequentially!
OMG there are lots of models! Which should I choose?
My opinion to this is to try them ALL. One wrong intuition for some buddies is that the more complex the model, the better the prediction will be. However this is NOT true. Sometimes a simple model can outperform a neural network. It just depends on the task you are working on and the data structure. So don't always try one model that "you think" is the best one, try at least several for comparison.
Ask!
No one can solve every question by themselves alone and it's never embarrassing to ask questions. Try to seek help from others if you are stuck in a trouble, be it a simple coding issue or a high-level problem about some models (P.S. always Google it before you ask, others' time is as valuable as yours). If you have friends who are good at data science, you can of course discuss with them. Otherwise, online platforms like Stack Exchange, Reddit and Quora can definitely help you out.
Hope you've had a good time!
I'm gonna stop here and I hope you find these 2 articles helpful. I'll definitely share some of my projects if I have the time to organize them a bit. Lemme copy the ending of my last article to here again: "don't be the one who will be fouled by the AI revolution, be the one who makes it happen" : )
If you like my posts, please upvote, resteem and follow me @manfredcml!
如果喜歡小弟的文章,可以upvote, resteem或follow @manfredcml支持!
English articles 英語文章:
Do you have to be a "genius" to work on machine learning?
Be a smart gambler! #1 - Gambler's fallacy
Let's play a game #1 - Prisoner's Dilemma
Paradox is fun! #1 - Boy or Girl?
No solution! #1 - Prime numbers
Bilingual articles 雙語文章:
Welcome to the world of mahjong! 歡迎來到麻雀教室! #1
No solution! #2 - P vs NP Problem / 無解 #2 - P vs NP問題
Paradox is fun! #2 - Will you switch the door? 趣味悖論 #2 - 你會換另一道門嗎?
I also think Kaggle is a good web for machine learning developers. A lot of competitions there offer** real **data and you can also find some report online from the winners of previous competitions (not always available but some really have it). That way we can learn how they develop their successful model and there's always something to gain from that, be that insights into the data or the new modelling methods and so on!