Quick project info
This software is a "mining" software for a family of cryptocurrencies based on so-called Proof-of-Capacity. The best information about that concept is available in info materials from the BURST coin. You can learn some technical bits from resources on their home page, for example this whitepaper.
Repository
GitHub: https://github.com/quetzalcoatl/blagominer/
Sidenote: Repository was copied around a few times by previous mantainers. If you're interested in its history, see my first post about Blagominer.
New Features
This submission is related to my work on this project between Jun 28, 2019 - Jun 26, 2019. I've added two very interesting features and released it as v2.300001.0.
A bit before that, Jun 25 - Jun 13, I made a cleanup and bug fixing session I also wanted to write about, but I was so busy I didn't notice so much time has passed already! Actually, during that time I made my first release: lots of bugfixes, and option to configure URLs, and automatic selection and switching between elevated and non-elevated run.
Today however, I have something even better!
1. Multimining! Not just dual mining - mine any number of PoC coins.
Feature branch for this change is feature/multimining-manycoins. However, the code required so much work before I could even start the feature itself, that I actually made a preliminary branch: feature/pre-multimining-cleanups where I did all the preceding "boring" cleanups and refactorings.
The main problem with the code was its overabundant use of static global variables. And lack of generalization in many places. Blagominer was adapted to be able to dual-mine BURST and BHD, but many things were programmed directly with that in mind and no vision for the future. For example, coin configuration was kept in global burst and bhd variables and used all over the place. The code responsible for reading configuration from miner.conf file was totally duplicated and hardcoded for reading from burst and bhd sections. Networking threads had dedicated code to each of the coins, logging code switched between two coins with use of hardcoded enum (which had 'burst' and 'bhd' entries). Even simple things like printing out the coin name was hardcoded to switch between "burst"/"bhd", even though the code already had a t_coin_info structure, where you'd normally look for a coinname..
After analyzing various pieces of the global state related to coin configuration, internal state management, thread management and CSV logging, I moved it all to t_coin_info and its supporting structures. Then I once again revisited the configuration-reading code and linked creating t_coin_info entries to scanning the config file and looking for coin configuration nodes (as opposed to reading from two specific notes and putting that into two specific t_coin_infos) and basically the code was ready for multimining!
What does it mean for the end user?
Blagominer can now prioritize&switch between any number of coins, not only BURST and BHD, as long as the coins in question use compatible plot file formats.
Here's a screenshot of a triple-mining BURST+BHD+BOOM:
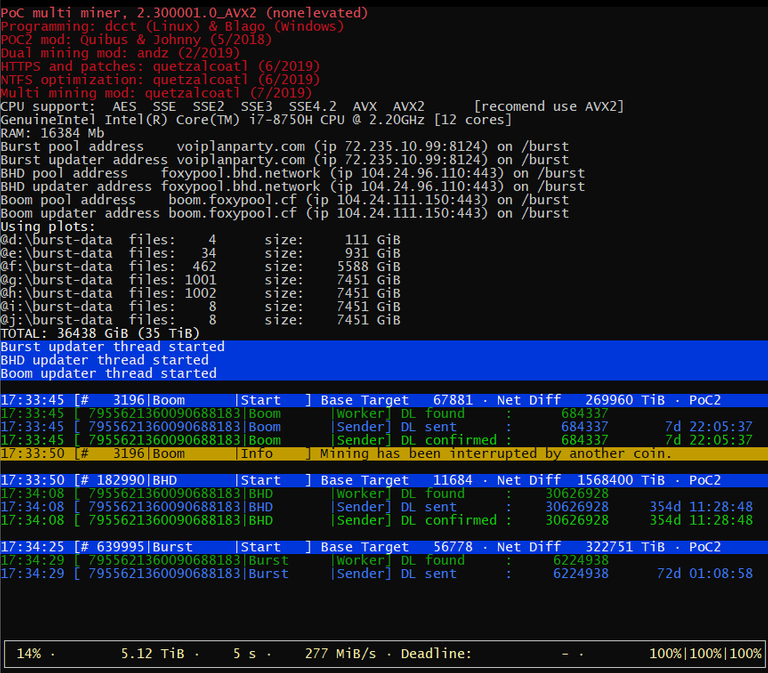
and a sample configuration file
Please take care: the config file format changed slightly. You have to update your config files, or else the new version will not understand them. That's why I changed application's major version from 1 to 2 (kind of a semver, but I still need to clean up versioning scheme a bit).
I also changed the name on the title screen, since "BURST/BHD miner" no longer makes sense. The title screen will now advertise the application as "PoC multi miner", while the code name stays as it was: Blagominer.
2. NTFS file ordering - less drive clicking
Feature branch for this change is feature/optimize-multifile-seeking.
I use Blagominer myself and I noticed that some of my drives were really noisy, while other were working relatively silent. Same brand, same model, probably a different time of purchase. These louder ones also had noticeably lower read times. SMART data didn't reveal any failures or real problems. After inspecting it turned out that those were the oldest drives which I plotted with TurboPlotter, and where I set up a maximum plot file size of 8 GB. I remember I was experimenting with various settings, and writing on SMR Seagate drives took ages, and I finally decided to split the files to that 8 GB chunks so it's easier to continue when something crashes/etc.
...and that was rather a bad idea.
First of all, I didn't know about details of POC2 file format which was optimized for speeding up reading from large files. If I kept it as a one large file, all nonces could be read in one seek and one go. My settings caused splitting the plot into hundreds of files, now each one has to be read separately. This alone lowers reading speed and partially nullifies gains from POC2 optimisation.
However, even worse effect came from the TurboPlotter. It turns out that when it is given a max-file-size option, it splits the plot file accordingly, keeps track of nonce space to cover it fully, but it writes the files to the drive in some weird order, far from numeric or alphabetic order that I would expect. Blagominer in turn always read the files in the order of nonces. That caused constant back-n-forth seeking to reach next file in line, randomly scattered over the whole drive. Aside from lowering the speed, it also shortens the drive's lifespan.
There were only two solutions: either replot all those SMR drives, or try to change the file reading order.
I didn't fancy replotting (at least for now), so first piece to this puzzle was to find out the physical location of all files. The operating system surely knows it, every "defragmenter" tool is able to retrieve it, so it certainly was possible. I have found this old post which discussed exactly this problem. On Windows, it actually boils down to two calls to DeviceIoControl with FSCTL_GET_RETRIEVAL_POINTERS and IOCTL_VOLUME_LOGICAL_TO_PHYSICAL messages. Most probably the latter wasn't really necessary to reorder the files.
After changing the file access so that files are read in order of their physical location on the drive, the overall reading speed rose 10 to 15% depending mostly on the drive size. Also, the noise completely disappeared. Drives stopped seeking back-n-forth, now all the seeking between files is done in one direction, forward, which is perfect for the drive itself.
This option has negligible effect on drives with very few plot files, but has a great potential when for any reason you have 100 or more plot files a physical disk. Also, the net effect may be none if your plot files are fragmented, since this option scans files only looking at they show up on the drive, not how all their parts are scattered on the drive. I considered additional option for optimizing reads for this case, but for now its implementation seems awfully complex and not worth the effort. If you have hundreds of plot files on a drive and also these files are fragmented, I suggest quickformat and replotting. I plan to replot my SMR drives to remove that file jungle, just not right now.
I don't know of any case where this option would induce any negative effects. Determining the physical order of files takes some time, seen as slow 'spinning up the speeds' in the UI, but reading them in-order seems to make up for that with a large margin. Nevertheless, this is a new option and totally an experiment, so it's OFF by default.
You can turn this option simply by adding a '@' before a directory path in the configuration file. For example, if a path was c:\\data\\plots, now it would be @c:\\data\\plots. Simple as that.
v2.300001.0looks like an interesting versioning convention. What's up with that sooo many decimal points? :)Good luck with the progress. Multi-mining looks like a great achievement.
Your contribution has been evaluated according to Utopian policies and guidelines, as well as a predefined set of questions pertaining to the category.
To view those questions and the relevant answers related to your post, click here.
Need help? Chat with us on Discord.
[utopian-moderator]
Thank you for your review, @emrebeyler! Keep up the good work!
Hi, @ookamisuuhaisha!
You just got a 0.05% upvote from SteemPlus!
To get higher upvotes, earn more SteemPlus Points (SPP). On your Steemit wallet, check your SPP balance and click on "How to earn SPP?" to find out all the ways to earn.
If you're not using SteemPlus yet, please check our last posts in here to see the many ways in which SteemPlus can improve your Steem experience on Steemit and Busy.
Hi @ookamisuuhaisha!
Your post was upvoted by @steem-ua, new Steem dApp, using UserAuthority for algorithmic post curation!
Your post is eligible for our upvote, thanks to our collaboration with @utopian-io!
Feel free to join our @steem-ua Discord server
Hey, @ookamisuuhaisha!
Thanks for contributing on Utopian.
We’re already looking forward to your next contribution!
Get higher incentives and support Utopian.io!
Simply set @utopian.pay as a 5% (or higher) payout beneficiary on your contribution post (via SteemPlus or Steeditor).
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!
Defended (38.18%)
Summoned by @ookamisuuhaisha
Sneaky Ninja supports @youarehope and @tarc with a percentage of all bids.
Everything You Need To Know About Sneaky Ninja
woosh
Congratulations @ookamisuuhaisha! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOP